Musings about music production, psychoacoustics, sound synthesis and anything else we find interesting, from the Centre for Digital Music's Audio Engineering research team.
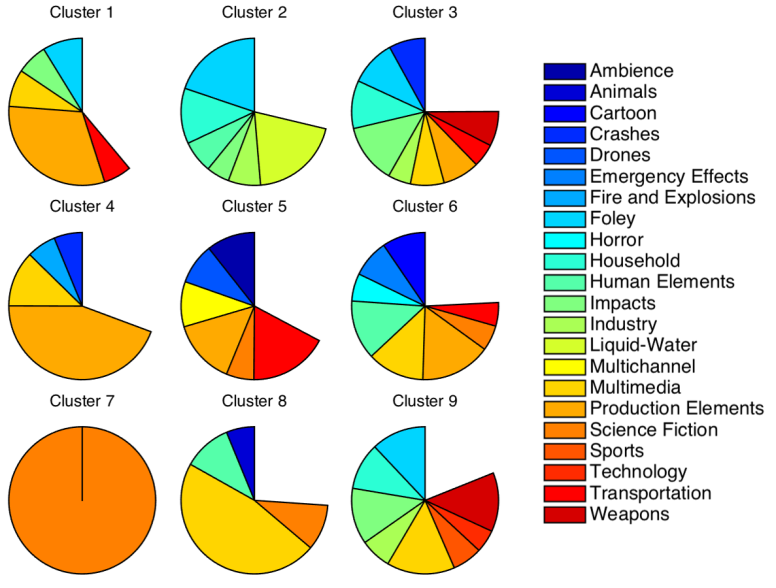
A taxonomy of sound effects is useful for a range of reasons. Sound designers often spend considerable time searching for sound effects. Classically, sound effects are arranged based on some key word tagging, and based on what caused the sound to be created – such as bacon cooking would have the name “BaconCook”, the tags “Bacon Cook, Sizzle, Open Pan, Food” and be placed in the category “cooking”. However, most sound designers know that the sound of frying bacon can sound very similar to the sound of rain (See this TED talk for more info), but rain is in an entirely different folder, in a different section of the SFx Library.
The approach, is to analyse the raw content of the audio files in the sound effects library, and allow a computer to determine which sounds are similar, based on the actual sonic content of the sound sample. As such, the sounds of rain and frying bacon will be placed much closer together, allowing a sound designer to quickly and easily find related sounds that relate to each other.
Here’s a figure from the paper, comparing the generated taxonomy to the original sound effect library classification scheme.
by Rod Selfridge & David Moffat. Photos by Beici Liang.
Audio Mostly – Augmented and Participatory Sound and Music Experiences, was held at Queen Mary University of London between 23 – 26 August. The conference brought together a wide variety of audio and music designers, technologists, practitioners and enthusiasts from all over the world.
The opening day of the conference ran in parallel with the Web Audio Conference, also being held at Queen Mary, with sessions open to all delegates. The day opened with a joint Keynote from the computer scientist and author of the highly influential sound effect book – Designing Sound, Andy Farnell. Andy covered a number of topics and invited audience participation which grew into a discussion regarding intellectual property – the pros and cons if it was done away with.
Andy Farnell
The paper session then opened with an interesting talk by Luca Turchet from Queen Mary’s Centre for Digital Music. Luca presented his paper on The Hyper Mandolin, an augmented music instrument allowing real-time control of digital effects and sound generators. The session concluded with the second talk I’ve seen in as many months by Charles Martin. This time Charles presented Deep Models for Ensemble Touch-Screen Improvisation where an artificial neural network model has been used to implement a live performance and sniffed touch gestures of three virtual players.
In the afternoon, I got to present my paper, co-authored by David Moffat and Josh Reiss, on a Physically Derived Sound Synthesis Model of a Propeller. Here I continue the theme of my PhD by applying equations obtained through fluid dynamics research to generate authentic sound synthesis models.
Rod Selfridge
The final session of the day saw Geraint Wiggins, our former Head of School at EECS, Queen Mary, present Callum Goddard’s work on designing Computationally Creative Musical Performance Systems, looking at questions like what makes performance virtuosic and how this can be implemented using the Creative Systems Framework.
The oral sessions continued throughout Thursday, one presentation that I found interesting was by Anna Xambo titles Turn-Taking and Chatting in Collaborative Music Live Coding. In this research the authors explored collaborative music live coding using the live coding environment and pedagogical tool EarSketch, focusing on the benefits to both performance and education.
Thursday’s Keynote was by Goldsmith’s Rebecca Fiebrink, who was mentioned in a previous blog, discussing how machine learning can be used to support human creative experiences, aiding human designers for rapid prototyping and refinement of new interactions within sound and media.
Rebecca Fiebrink
The Gala Dinner and Boat Cruise was held on Thursday evening where all the delegates were taken on a boat up and down the Thames, seeing the sites and enjoying food and drink. Prizes were awarded and appreciation expressed to the excellent volunteers, technical teams, committee members and chairpersons who brought together the event.
Tower Bridge
A session on Sports Augmentation and Health / Safety Monitoring was held on Friday Morning which included a number of excellent talks. The presentation of the conference went to Tim Ryan who presented his paper on 2K-Reality: An Acoustic Sports Entertainment Augmentation for Pickup Basketball Play Spaces. Tim re-contextualises sounds appropriated from a National Basketball Association (NBA) video game to create interactive sonic experiences for players and spectators. I was lucky enough to have a play around with this system during a coffee break and can easily see how it could give an amazing experience for basketball enthusiasts, young and old, as well as drawing in a crowd to share.
Workshops ran on Friday afternoon. I went to Andy Farnell’s Zero to Hero Pure Data Workshop where participants managed to go from scratch to having a working bass drum, snare and high-hat synthesis models. Andy managed to illustrate how quickly these could be developed and included in a simple sequencer to give a basic drum machine.
Throughout the conference a number of fixed media, demos were available for delegates to view as well as poster sessions where authors presented their work.
Alessia Milo
Live music events were held on both Wednesday and Friday. A joint session titled Web Audio Mostly Concert was held on Wednesday which was a joint event for delegates of Audio Mostly and the Web Audio Conference. This included an augmented reality musical performance, a human-playable robotic zither, the Hyper Mandolin and DJs.
The Audio Mostly Concert on the Friday included a Transmusicking performance from a laptop orchestra from around the world, where 14 different performers collaborated online. The performance was curated by Anna Xambo. Alan Chamberlain and David De Roure performed The Gift of the Algorithm, which was a computer music performance inspired by Ada Lovelace. The wood and the water was an immersive performance of interactivity and gestural control of both a Harp and lighting for the performance, by Balandino Di Donato and Eleanor Turner. GrainField, by Benjamin Matuszewski and Norbert Schnell, was an interactive audio performance that demanded entire audience involvement, for the performance to exist, this collective improvisational piece demonstrated a how digital technology can really be used to augment the traditional musical experience. GrainField was awarded the prize for the best musical performance.
Adib Mehrabi
The final day of the conference was a full day’s workshop. I attended the one titled Designing Sounds in the Cloud. The morning was spent presenting two ongoing European Horizon 2020 projects, Audio Commons (www.audiocommons.org/) and Rapid-Mix. The Audio Commons initiative aims to promote the use of open audio content by providing a digital ecosystem that connects content providers and creative end users. The Rapid-Mix project focuses on multimodal and procedural interactions leveraging on rich sensing capabilities, machine learning and embodied ways to interact with sound.
Before lunch we took part in a sound walk around the Queen Mary Mile End Campus, with one of each group blindfolded, informing the other what they could hear. The afternoon session had teams of participants designing and prototyping new ways to use the APIs from each of the two Horizon 2020 projects – very much in the feel of a hackathon. We devised a system which captured expressive Italian hand gestures using the Leap Motion and classified them using machine learning techniques. Then in pure data each new classification triggered a sound effect taken from the Freesound website (part of the audio commons project). If time would have allowed the project would have been extended to have pure data link to the audio commons API and play sound effects straight from the web.
Overall, I found the conference informative, yet informal, enjoyable and inclusive. The social events were spectacular and ones that will be remembered by delegates for a long time.
I’ve been meaning to write this blog entry for a while, and I’ve finally gotten around to it. At the 142nd AES Convention, there were two papers that really stood out which weren’t discussed in our convention preview or convention wrap-up. One was about Acoustic Energy Harvesting, which we discussed a few weeks ago, and the other was titled ‘The DFA Fader: Exploring the Power of Suggestion in Loudness The DFA Fader: Exploring the Power of Suggestion in Loudness Judgments.’ When I mentioned this paper to others, their response was always the same, “What’s a DFA Fader?” . Well, the answer is hinted at in the title of this blog entry.
The basic idea is that musicians often give instructions to the sound engineer that he or she can’t or doesn’t want to follow. For instance, a vocalist might say “Turn me up” in a soundcheck, but the sound engineer knows that the vocals are at a nice level already and any more amplification might cause feedback. Sometimes, this sort of thing can be communicated back to the musician in a nice way. But there’s also the fallback option; a fader on the mixing console that “Does F*** All”, aka DFA. The engineer can slide the fader or twiddle an unconnected dial, smile back and say ‘Ok, does this sound a bit better?’.
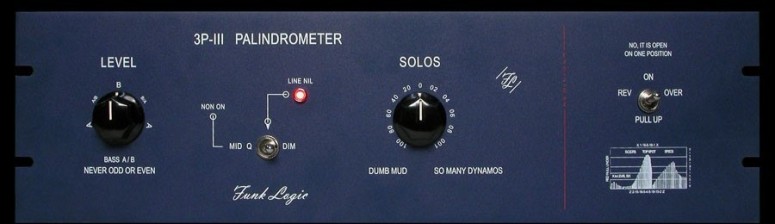
A couple of companies have had fun with this idea. Funk Logic’s Palindrometer, shown below, is nothing more than a filler for empty rack space. Its an interface that looks like it might do something, but at best, it just flashes some LEDs when one toggles switches and turns the knobs.
RANE have the PI 14 Pseudoacoustic Infector . Its worth checking out the full description, complete with product review and data sheets. I especially like the schematic, copied below.
And in 2014, our own Brecht De Man released The Wire, a freely available VST and AudioUnit plug-in that emulates a gold-plated, balanced, 100% lossless audio connector.
Anyway, the authors of this paper had the bright idea of doing legitimate subjective evaluation of DFA faders. They didn’t make jokes in the paper, not even to explain the DFA acronym. They took 22 participants and divided them into an 11 person control group and an 11 person test group. In the control group, each subject participated in twenty trials where two identical musical excerpts were presented and the subject had to rate the difference in loudness of vocals between the two excerpts. Only ten excerpts were used, so each pair was used in two trials. In the test group, a sound engineer was present and he made scripted suggestions that he was adjusting the levels in each trial. He could be seen, but participants couldn’t see his hands moving on the console.
Not surprisingly, most trials showed a statistically significant difference between test and control groups, confirming the effectiveness of verbal suggestions associated with the DFA fader. And the authors picked up on an interesting point; results were far more significant for stimuli where vocals were masked by other instruments. This links the work to psychoacoustic studies. Not only is our perception of loudness and timbre influenced by the presence of a masker, but we have a more difficult time judging loudness and hence are more likely to accept the suggestion from an expert.
The authors did an excellent job of critiquing their results. But unfortunately, the full data was not made available with the paper. So we are left with a lot of questions. What were these scripted suggestions? It could make a big difference if the engineer said “I’m going to turn the vocals way up” versus “Let me try something. Does it sound any different now?” And were some participants immune to the suggestions? And because participants couldn’t see a fader being adjusted (interviews with sound engineers had stressed the importance of verbal suggestions), we don’t know how that could influence results.
There is something else that’s very interesting about this. It’s a ‘false experiment’. The whole listening test is a trick since for all participants and in all trials, there was never any loudness differences between the two presented stimuli. So indirectly, it looks at an ‘auditory placebo effect’ that is more fundamental than DFA faders. What were the ratings for loudness differences that participants gave? For the control group especially, did they judge these differences to be small because they trusted their ears, or large because they knew that loudness judging is the nature of the test? Perhaps there is a natural uncertainty in loudness perception regardless of bias. How much weaker does a listener’s judgment become when repeatedly asked to make very subtle choices in a listening test? There’s been some prior work tackling some of these questions, but I think this DFA Faders paper opened up a lot of avenues of interesting research.
intelligentsoundengineering
2:07 pm on August 7, 2017 Tags: female inventors, women in engineering, women in science
The Heyser lecture is a distinguished talk given at each AES Convention by eminent individuals in audio engineering and related fields. At the 140th AES Convention, Rozenn Nicol was the Heyser lecturer. This was well-deserved, and she has made major contributions to the field of immersive audio. But what was shocking about this is that she is the first woman Heyser lecturer. Its an indicator that woman are under-represented and under-recognised in the field. With that in mind, I’d like to highlight some women who have made major contributions to the field, especially in research and innovation.
Birgitta Berglund led major research into the impact of noise on communities. Her influential research resulted in guidelines from the World Health Organisation, and greatly advanced our understanding of noise and its effects on society. She was the 2009 IOA Rayleigh medal recipient.
Marina Bosi is a past AES president of the AES. She has been instrumental in the development of standards for audio coding and digital content management standards and formats, including develop the AC-2, AC-3, and MPEG-2 Advanced Audio Coding technologies,
Anne-Marie Bruneau has been one of the most important researchers on electrodynamic loudspeaker design, exploring motion impedance and radiation patterns, as well as establishing some of the main analysis and measurement approaches used today. She co-founded the Laboratoire d’Acoustique de l’Université du Maine, now a leading acoustics research center.
Ilene J. Busch-Vishniac is responsible for major advances in the theory and understanding of electret microphones, as well as patenting several new designs. She received the ASA R. Bruce Lindsay Award in 1987, and the Silver Medal in Engineering Acoustics in 2001. President of the ASA 2003-4.
Elizabeth (Betsy) Cohen was the first female president of the Audio Engineering Society. She was presented with the AES Fellowship Award in 1995 for contributions to understanding the acoustics and psychoacoustics of sound in rooms. In 2001, she was presented with the AES Citation Award for pioneering the technology enabling collaborative multichannel performance over the broadband internet.
Poppy Crum is head scientist at Dolby Laboratories whose research involves computer research in music and acoustics. At Dolby, she is responsible for integrating neuroscience and knowledge of sensory perception into algorithm design, technological development, and technology strategy.
Delia Derbyshire (1937-2001) was an innovator in electronic music who pushed the boundaries of technology and composition. She is most well-known for her electronic arrangement of the theme for Doctor Who, an important example of Musique Concrète. Each note was individually crafted by cutting, splicing, and stretching or compressing segments of analogue tape which contained recordings of a plucked string, oscillators and white noise. Here’s a video detailing a lot of the effects she used, which have now become popular tools in digital music production.
Ann Dowling is the first female president of the Royal Academy of Engineering. Her research focuses on noise analysis and reduction, especially from engines, and she is a leading educator in acoustics. A quick glance at google scholar shows how influential her research has been.
Marion Downs was an audiometrist at Colorado Medical Center in Denver, who invented the tests used to measure hearing both In newly born babies and in fetuses.
Judy Dubno is Director of Hearing Research at the Medical University of South Carolina. Her research focuses on human auditory function, with emphasis on the processing of auditory information and the recognition of speech, and how these abilities change in adverse listening conditions, with age, and with hearing loss. Recipient of the James Jerger Career Award for Research in Audiology from the American Academy of Audiology and Carhart Memorial Lecturer for the American Auditory Society. President of the ASA in 2014-15.
Rebecca Fiebrink researches Human Computer Interaction (HCI) and its application of machine learning to real-time, interactive, and creative domains. She is the creator of the popular Wekinator, which allows anyone to use machine learning to build new musical instruments, real-time music information retrieval and audio analysis systems, computer listening systems and more.
Katherine Safford Harris pioneered EMG studies of speech production and auditory perception. Her research was fundamental to speech recognition, speech synthesis, reading machines for the blind, and the motor theory of speech perception. She was elected Fellow of the ASA, the AAAS, the American Speech-Language-Hearing Association, and the New York Academy of Sciences. She was President of the ASA (2000-2001), awarded the Silver Medal in 2005 and Gold Medal in 2007.
Rhona Hellman was a Fellow of the ASA. She was a distinguished hearing scientist and preeminent expert in auditory perceptual phenomena. Her research spanned almost 50 years, beginning in 1960. She tackled almost every aspect of loudness, and the work resulted in major advances and developments of loudness standards.
Mara Helmuth developed software for composition and improvisation involving granular synthesis. Throughout the 1990s, she paved the way forward by exploring and implementing systems for collaborative performance over the Internet. From 2008-10 she was President of the International Computer Music Association.
Carlene Hutchins (1911-2009) was a leading researcher in the study of violin acoustics, with over a hundred publications in the field. She was founder and president of the Catgut Society, an organization devoted to the study and appreciation of stringed instruments .
Sophie Germain (1776-1831) was a French mathematician, scientist and philosopher. She won a major prize from the French Academy of Sciences for developing a theory to explain the vibration of plates due to sound. The history behind her contribution, and the reactions of leading French mathematicians to having a female of similar calibre in their midst, is fascinating. Joseph Fourier, whose work underpins much of audio signal processing, was a champion of her work.
Bronwyn Jones was a psychoacoustician at the CBS Technology Center during the 70s and 80s. In seminal work with co-author Emil Torrick, she developed one of the first loudness meters, incorporating both psychoacoustic principles and detailed listening tests. It paved the way for what became major initiatives for loudness measurement, and in some ways outperforms the modern ITU 1770 standard
Bozena Kostek is editor of the Journal of the Audio Engineering Society. Her most significant contributions include the applications of neural networks, fuzzy logic and rough sets to musical acoustics, and the application of data processing and information retrieval to the psychophysiology of hearing. Her research has garnered dozens of prizes and awards.
Daphne Oram (1925 –2003) was a pioneer of ‘musique concrete’ and a central figure in the evolution of electronic music. She devised the Oramics technique for creating electronic sounds, co-founded the BBC Radiophonic Workshop, and was possibly the first woman to direct an electronic music studio, to set up a personal electronic music studio and to design and construct an electronic musical instrument.
Carla Scaletti is an innovator in computer generated music. She designed the Kyma sound generation computer language in 1986 and co-founded Symbolic Sound Corporation in 1989. Kyma is one of the first graphical programming languages for real time digital audio signal processing, a precursor to MaxMSP and PureData, and is still popular today.
Bridget Shield was professor of acoustics at London Southbank University. Her research is most significant in our understanding of the effects of noise on children, and has influenced many government initiatives. From 2012-14, she was the first female President of the Institute of Acoustics.
Laurie Spiegel created one of the first computer-based music composition programs, Music Mouse: an Intelligent Instrument, which also has some early examples of algorithmic composition and intelligent automation, both of which are hot research topics today.
Mary Desiree Waller (1886-1959) wrote a definitive treatise on Chladni figures, which are the shapes and patterns made by surface vibrations due to sound, see Sophie Germain, above. It gave far deeper insight into the figures than any previous work.
The post Behind the spectacular sound of ‘Dunkirk’ – with Richard King: appeared first on A Sound Effect. Its an interesting interview giving deep insights into sound design and soundscape creation for film. It caught my attention first because of the mention of Richard King. But its not Richard King, Grammy award winning professor in sound recording at University of McGill. Its the other one, the Oscar award winning supervising sound editor at Warner Brothers Sound.
We collaborated with Prof. Richard King on a couple of papers. In [1], we conducted an experiment where eight songs were each mixed by eight different engineers. We analysed audio features from the multitracks and mixes. This allowed us to test various assumed rules of mixing practice. In the follow-up [2], the mixes were all rated by experienced test subjects. We used the ratings to investigate relationships between perceived mix quality and sonic features of the mixes.
Intelligent Sound Engineering are pleased to announce our lead academic, Joshua D Reiss has been promoted to Professor of Audio Engineering.
Professor Reiss holds degrees in Physics and Mathematics, and a PhD in Chaos Theory from Georgia Institute of Technology. He has been an academic with the Centre for Digital Music in the Electronic Engineering and Computer Science department at Queen Mary University of London since 2003. His primary focus of research is on state-of-the-art signal processing techniques for sound engineering, publishing over 160 scientific papers and authoring the book “Audio Effects: Theory, Implementation and Application” together with Andrew McPherson. Along with pioneering research into intelligent audio production technologies, Professor Reiss also focuses on state of the art sound synthesis techniques.
Professor Reiss is a visiting Professor at Birmingham City University, an Enterprise Fellow of the Royal Academy of Engineering and has been a governor of the Audio Engineering Society from 2013 to present.








 Poppy Crum is head scientist at Dolby Laboratories whose research involves computer research in music and acoustics. At Dolby, she is responsible for integrating neuroscience and knowledge of sensory perception into algorithm design, technological development, and technology strategy.
Poppy Crum is head scientist at Dolby Laboratories whose research involves computer research in music and acoustics. At Dolby, she is responsible for integrating neuroscience and knowledge of sensory perception into algorithm design, technological development, and technology strategy. Rebecca Fiebrink researches Human Computer Interaction (HCI) and its application of machine learning to real-time, interactive, and creative domains. She is the creator of the popular Wekinator, which allows anyone to use machine learning to build new musical instruments, real-time music information retrieval and audio analysis systems, computer listening systems and more.
Rebecca Fiebrink researches Human Computer Interaction (HCI) and its application of machine learning to real-time, interactive, and creative domains. She is the creator of the popular Wekinator, which allows anyone to use machine learning to build new musical instruments, real-time music information retrieval and audio analysis systems, computer listening systems and more. Carlene Hutchins
Carlene Hutchins  Carla Scaletti is an innovator in computer generated music. She designed the Kyma sound generation computer language in 1986 and co-founded Symbolic Sound Corporation in 1989. Kyma is one of the first graphical programming languages for real time digital audio signal processing, a precursor to MaxMSP and PureData, and is still popular today.
Carla Scaletti is an innovator in computer generated music. She designed the Kyma sound generation computer language in 1986 and co-founded Symbolic Sound Corporation in 1989. Kyma is one of the first graphical programming languages for real time digital audio signal processing, a precursor to MaxMSP and PureData, and is still popular today. Mary Desiree Waller (1886-1959) wrote a definitive treatise on Chladni figures, which are the shapes and patterns made by surface vibrations due to sound, see Sophie Germain, above. It gave
Mary Desiree Waller (1886-1959) wrote a definitive treatise on Chladni figures, which are the shapes and patterns made by surface vibrations due to sound, see Sophie Germain, above. It gave 
