Musings about music production, psychoacoustics, sound synthesis and anything else we find interesting, from the Centre for Digital Music's Audio Engineering research team.
The next Audio Engineering Society Convention will be in May, in the Hague, the Netherlands. Its expected to be the first major AES event with an in-person presence (though it has an online component too) since the whole Covid situation began. It will cover the whole field of audio engineering, with workshops, panel discussions, tutorials, keynotes, recording competitions and more. And attendees cover the full range of students, educators, researchers, audiophiles, professional engineers and industry representatives. I’m always focused on the Technical Program for these events, where lots of new research is published and presented, and I expect this one to be great. Just based on some expected submissions that I know of, there’s sure to be some great papers on sound synthesis, game audio, immersive and spatial audio, higher quality and deeper understanding of audio effects, plenty of machine learning and neural network, novel mixing and mastering tools, and lots of new psychoacoustics research. And that’s just the ones I’ve heard about! Its definitely not too late to submit your own work, see the Call for Submissions. The deadline for full paper submissions (Category 1) or abstract + precis submissions (Category 2) is February 15th. And the deadline for abstract-only submissions (Category 3) is March 1st. In all cases, you submit a full paper for the final version if accepted (though for Category 3 this is optional). So the main difference between the 3 categories is the depth of reviewing, from full peer review for initial paper submissions to ‘light touch’ reviewing for an initial abstract submission. For those who aren’t familiar with it, great research has been, and continues to be, presented at AES conventions. The very first music composition on a digital computer was presented at the 9th AES Convention in 1957. Schroeder’s reverberator first appeared there, the invention of the parametric equalizer was announced and explained there in 1972, Farina’s work on the swept sine technique for room response estimation was unveiled there, and has received over 1365 citations. Other famous firsts from the Technical program include the introduction of Feedback Delay Networks, Gardner’s famous paper on zero delay convolution, now used in almost all fast convolution algorithms, the unveiling of Spatial audio object coding, and the Gerzon-Craven noise shaping theorem, which is at the heart of many A to D and D to A converters. So please consider submitting your research there, and I hope to see you there too, whether virtually or in person.
We haven’t done a lot of blogging recently, but for a good reason; there’s an inverse relationship between how often we post blog entries and how busy we are trying to do something interesting. Now we’ve done it, we can talk about it, and today, we can launch it!
Procedural audio is a big area of research for us, which we have discussed in previous blog entries about aeroacoustics, whistles, swinging swords , propellers and thunder. This is sound synthesis, but with some additional requirements. Its usually intended for use in interactive content (games), so it needs to generate sound in real-time, and adapt to changing inputs.
There are some existing efforts to offer procedural audio. However, they usually focus on a few specific sounds, which means sound designers still need sound effect libraries for most sound effects. And some efforts still involve manipulating sound samples. Which means they aren’t truly procedural. But if you can create any sound effect, then you can do away with the sample libraries (almost) entirely, and procedurally generate entire auditory worlds.
And we’ve created a company that aims to do just that. Nemisindo, named after the Zulu for “sounds/noise” offer sound design services based on their innovative procedural audio technology. They are launching a new online service, https://nemisindo.com, that allows users to create sound effects for games, film and VR without the need for vast libraries of sounds.
The following video gives a taste of the technology and the range of services they offer.
Nemisindo’s new platform provides a browser-based service with tools to create sounds from over 70 classes (engines, footsteps, explosions…) and over 700 preselected settings (diesel generator engine, motorbike, Jetsons jet…). It can be used to create almost any sound effect from scratch, and in real-time, based on intuitive controls guided by the user.
If someone wants a ‘whoosh’ sound for their game, or footsteps, gunshots, a raging fire or a gentle summer shower, they just tell the system what they’re looking for and adjust the sound while it’s being created. And unlike other technologies that simply use pre-recorded sounds, Nemisindo’s platform generates sounds that have never been recorded, a dragon roaring, for instance, light sabres swinging and space cannons firing. These sound effects can also be shaped and crafted at the point of creation by the user, breaking through limitations of sampled sounds.
Nemisindo has already caught the attention of Epic Games, with the spinout receiving an Epic MegaGrant to develop procedural audio for the Unreal game engine.
The new service from Nemisindo launches today (18 August 2021) and can be accessed at nemisindo.com. For the first month, Nemisindo is offering a free trial period allowing registered users to download sounds for free. After the trial period ends, the system is still free to use, but sounds can be downloaded at a low individual cost or with a paid monthly subscription.
This is an unusual blog entry, in that the three topics in the title, death metal, green dance music, and Olympic sound design, have very little in common. But they are all activities that the team here have been involved with recently, outside of our normal research, which are worth mentioning.
Finally, I was asked to write an article for The Conversation about sound design in the Olympics. A quick search showed that there were quite a few pieces written about this, but they all focused on the artificial crowd noise. Thats of course the big story, but I managed to find a different angle. Looking back, the modern Olympics that perhaps most revolutionised sound design in the past was… the 1964 Olympics in Tokyo. The technical aspects of the sound engineering involved were published in the July 1965 issue of the Journal of the Audio Engineering Society. So there’s a good story there on innovation in sound design, from Tokyo to Tokyo. The article, 3,600 microphones and counting: how the sound of the Olympics is created, was just published the moment I started writing this blog entry.
The gaming, film and virtual reality industries rely heavily on recorded samples for sound design. This has inherent limitations since the sound is fixed from the point of recording, leading to drawbacks such as repetition, storage, and lack of perceptually relevant controls.
Procedural audio offers a more flexible approach by allowing the parameters of a sound to be altered and sound to be generated from first principles. A natural choice for procedural audio is environmental sounds. They occur widely in creative industries content, and are notoriously difficult to capture. On-location sounds often cannot be used due to recording issues and unwanted background sounds, yet recordings from sample libraries are rarely a good match to an environmental scene.
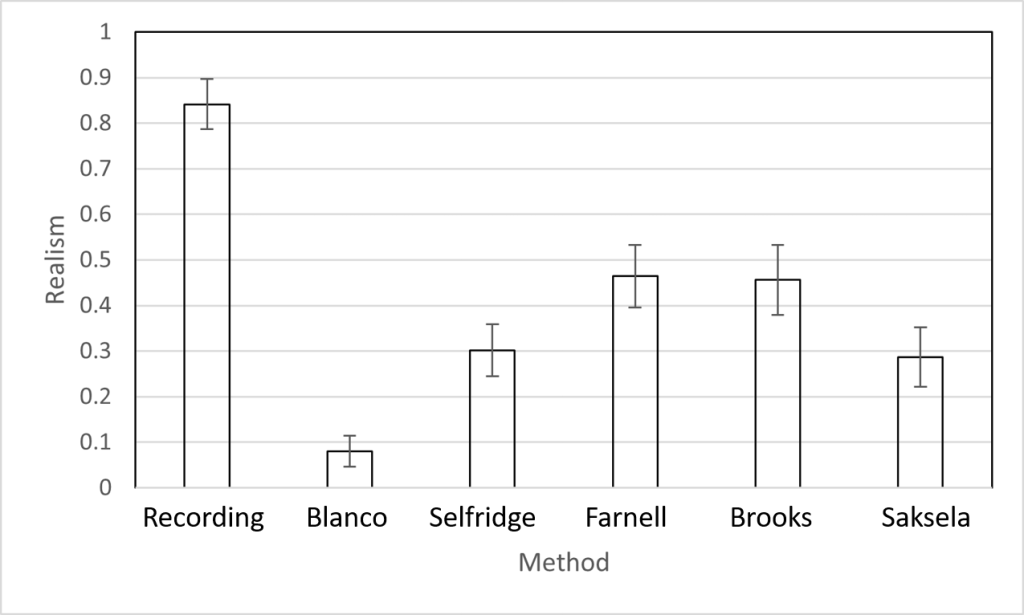
Thunder in particular, is highly relevant. It provides a sense of the environment and location, but can also be used to supplement the narrative and heighten the tension or foreboding in a scene. There exist a fair number of methods to simulate thunder. But no one’s ever actually sat down and evaluated these models. That’s what we did in,
J. D. Reiss, H. E. Tez, R. Selfridge, ‘A comparative perceptual evaluation of thunder synthesis techniques’, to appear at the 150th Audio Engineering Convention, 2021.
We looked at all the thunder synthesis models we could find, and in the end were able to compare five models and a recording of real thunder in a listening test. And here’s the key result,
This was surprising. None of the methods sound very close to the real thing. It didn’t matter whether it was a physical model, didn’t matter which type of physical modelling approach was used, or whether an entirely signal-based approach was applied. And yet there’s plenty of other sounds where procedural audio can sound indistinguishable from the real thing, see our previous blog post on applause foot .
We also played around with the code. Its clear that the methods could be improved. For instance, they all produced mono sounds (so we used a mono recording for comparison too), the physical models could be much, much faster, and most of the models used very simplistic approximation of lightning. So there’s a really nice PhD topic for someone to work on one day.
Besides showing the limitations of the current models, it also showed the need for better evaluation in sound synthesis research, and the benefits of making code and data available for others. On that note, we put the paper and all the relevant code, data, sound samples etc online at
We are part of a research network that has just been funded, focused around Aural diversity.
Aural Diversity arises from the observation that everybody hears differently. The assumption that we all possess a standard, undifferentiated pair of ears underpins most listening scenarios. Its the basis of many audio technologies, and has been a basis for much of our understanding of hearing and hearing perception. But the assumption is demonstrably incorrect, and taking it too far means that we miss out on many opportunities for advances in auditory science and audio engineering. We may well ask: whose ears are standard? whose ear has primacy? The network investigates the consequences of hearing differences in areas such as: music and performance, soundscape and sound studies, hearing sciences and acoustics, hearing care and hearing technologies, audio engineering and design, creative computing and AI, and indeed any field that has hearing or listening as a major component.
The term ‘auraldiversity’ echoes ‘neurodiversity’ as a way of distinguishing between ‘normal’ hearing, defined by BS ISO 226:2003 as that of a healthy 18-25 year-old, and atypical hearing (Drever 2018, ‘Primacy of the Ear’). This affects everybody to some degree. Each individual’s ears are uniquely shaped. We have all experienced temporary changes in hearing, such as when having a cold. And everybody goes through presbyacusis (age-related hearing loss) at varying rates after the teenage years.
More specific aural divergences are the result of an array of hearing differences or impairments which affect roughly 1.1 billion people worldwide (Lancet, 2013). These include noise-related, genetic, ototoxic, traumatic, and disorder-based hearing loss, some of which may cause full or partial deafness. However, “loss” is not the only form of impairment: auditory perceptual disorders such as tinnitus, hyperacusis and misophonia involve an increased sensitivity to sound.
And its been an issue in our research too. We’ve spent years developing automatic mixing systems that produce audio content like a sound engineer would (De Man et al 2017, ‘Ten Years of Automatic Mixing’). But to do that, we usually assume that there is a ‘right way’ to mix, and of course, it really depends on the listener, the listener’s environment, and many other factors. Our recent research has focused on developing simulators that allow anyone to hear the world as it really sounds to someone with hearing loss.
AHRC is funding the network for two years, beginning July 2021. The network is led by Andrew Hugill of the University of Leicester. The core partners are the Universities of Leicester, Salford, Nottingham, Leeds, Goldsmiths, Queen Mary University of London (the team behind this blog), and the Attenborough Arts Centre. The wider network includes many more universities and a host of organisations concerned with hearing and listening.
The network will stage five workshops, each with a different focus:
Hearing care and technologies. How the use of hearing technologies may affect music and everyday auditory experiences.
Scientific and clinical aspects. How an arts and humanities approach might complement, challenge, and enhance scientific investigation.
Acoustics of listening differently. How acoustic design of the built and digital environments can be improved.
Aural diversity in the soundscape. Includes a concert featuring new works by aurally diverse artists for an aurally diverse audience.
Music and performance. Use of new technologies in composition and performance.
We try to write a preview of the technical track for almost all recent Audio Engineering Society (AES) Conventions, see our entries on the 142nd, 143rd, 144th, 145th , 147th and 148th Conventions. Like the 148th Convention, the 149th convention, or just the AES Show, is an online event. But one challenge with these sorts of online events is that anything not on the main live stream can get overlooked. The technical papers are available on demand. So though many people can access them, perhaps more than would attend the presentation in person if possible. But they don’t have the feel of an event.
Hopefully, I can give you some idea of the exciting nature of these technical papers. And they really do present a lot of cutting edge and adventurous research. They unveil, for the first time some breakthrough technologies, and both surprising and significant advances in our understanding of audio engineering and related fields.
This time, since all the research papers are available throughout the Convention and beyond, starting Oct. 28th, I haven’t organised them by date. Instead, I’ve divided them into the regular technical papers (usually longer, with more reviewing), and the Engineering Briefs, or E-briefs. The E-briefs are typically smaller, often presenting work-in-progress, late-breaking or just unusual research. Though this time, the unusual appears in the regular papers too.
A must for audio educators is Brett Leonard’s ‘A Survey of Current Music Technology & Recording Arts Curriculum Order’. These sorts of programs are often ‘made up’ based on the experience and knowledge of the people involved. Brecht surveyed 35 institutions and analysed the results to establish a holistic framework for the structure of these degree programmes.
The idea of time-stretching as a live phenomenon might seem counterintuitive. For instance, how can you speed up a signal if its only just arriving? And if you slow it down, then surely after a while it lags far enough behind that it is no longer ‘live’. A novel solution is explored in Colin Malloy’s ‘An approach for implementing time-stretching as a live realtime audio effect’
The wonderfully titled ‘A Terribly Good Speaker: Understanding the Yamaha NS-10 Phenomenon,’ is all about how and why a low quality loudspeaker with bad reviews became seen as a ‘must have’ amongst many audio professionals. It looks like this presentation will have lessons for those who study marketing, business trends and consumer psychology in almost any sector, not just audio.
Just how good are musicians at tuning their instruments? Not very good, it seems. Or at least, that was what was found out in ‘Evaluating the accuracy of musicians and sound engineers in performing a common drum tuning exercise’, presented by Rob Toulson. But before you start with your favourite drummer joke, note that the participants were all experienced musicians or sound engineers, but not exclusively drummers. So it might be that everyone is bad at drum tuning, whether they’re used to carrying drumsticks around or not.
Champ Darabundit will present some interesting work on ‘Generalized Digital Second Order Systems Beyond Nyquist Frequency’, showing that the basic filter designs can be tuned to do a lot more than just what is covered in the textbooks. Its interesting and good work, but I have a minor issue with it. The paper only has one reference that isn’t a general overview or tutorial. But there’s lots of good, relevant related work, out there.
I’m involved in only one paper at this convention (shame!). But its well worth checking out. Angeliki Mourgela is presenting ‘Investigation of a Real-Time Hearing Loss Simulation for Audio Production’. It builds on an initial hearing loss simulator she presented at the 147th Convention, but now its higher quality, real-time and available as a VST plugin. This means that audio producers can easily preview what their content would sound like to most listeners with hearing loss.
Masking is an important and very interesting auditory phenomenon. With the emergence of immersive sound, there’s more and more research about spatial masking. But questions come up, like whether artificially panning a source to a location will result in masking the same way as actually placing a source at that location. ‘Spatial auditory masking caused by phantom sound images’, presented by Masayuki Nishiguchi, will show how spatial auditory masking works when sources are placed at virtual locations using rendering techniques.
Wow. When I first saw Moorer in the list of presenting authors, I thought ‘what a great coincidence that a presenter has the same last name as one of the great legends in audio engineering. But no, it really is James Moorer. We talked about him before in our blog about the greatest JAES papers of all time. And the abstract for his talk, ‘Audio in the New Millenium – Redux‘, is better than anything I could have written about the paper. He wrote, “In the author’s Heyser lecture in 2000, technological advances from the point of view of digital audio from 1980 to 2000 were summarized then projected 20 years into the future. This paper assesses those projections and comes to the somewhat startling conclusion that entertainment (digital video, digital audio, computer games) has become the driver of technology, displacing military and business forces.”
The paper with the most authors is presented by Lutz Ehrig. And he’ll be presenting a breakthrough, the first ‘Balanced Electrostatic All-Silicon MEMS Speakers’. If you don’t know what that is, you’re not alone. But its worth finding out, because this may be tomorrow’s widespread commercial technology.
If you recorded today, but only using equipment from 1955, would it really sound like a 65 year old recording? Clive Mead will present ‘Composing, Recording and Producing with Historical Equipment and Instrument Models’ which explores just that sort of question. He and his co-authors created and used models to simulate the recording technology and instruments, available at different points in recorded music history.
‘Degradation effects of water immersion on earbud audio quality,’ presented by Scott Beveridge, sounds at first like it might be very minor work, dipping earbuds in water and then listening to distorted sound from them. But I know a bit about the co-authors. They’re the type to apply rigorous, hardcore science to a problem. And it has practical applications too, since its leading towards methods by which consumers can measure the quality of their earbuds.
Forensic audio is a fascinating field, though most people have only come across it in film and TV shows like CSI, where detectives identify incriminating evidence buried in a very noisy recording. In ‘Forensic Interpretation and Processing of User Generated Audio Recordings’, audio forensics expert Rob Maher looks at how user generated recordings, like when many smartphones record a shooting, can be combined, synchronised and used as evidence.
Mark Waldrep presents a somewhat controversial paper, ‘Native High-Resolution versus Red Book Standard Audio: A Perceptual Discrimination Survey’. He sent out high resolution and CD quality recordings to over 450 participants, asking them to judge which was high resolution. The overall results were little better than guessing. But there were a very large number of questionable decisions in his methodology and interpretation of results. I expect this paper will get the online audiophile community talking for quite some time.
The research team here did some unpublished work that seemed to suggest that the mix had only a minimal effect on how people respond to music for untrained listeners, but this became more significant with trained sound engineers and musicians. Kelsey Taylor’s research suggests there’s a lot more to uncover here. In ‘I’m All Ears: What Do Untrained Listeners Perceive in a Raw Mix versus a Refined Mix?’, she performed structured interviews and found that untrained listeners perceive a lot of mixing aspects, but use different terms to describe it.
Staying on the subject of loudness, Kazuma Watanabe presents ‘The Reality of The Loudness War in Japan -A Case Study on Japanese Popular Music’. This loudness war, the overuse of dynamic range compression, has resulted in lower quality recordings (and annoyingly loud TV and radio ads). It also led to measures like the ITU standard. Watanabe and co-authors measured the increased loudness over the last 30 years, and make a strong
Remember to check the AES E-Library which has all the full papers for all the presentations mentioned here, including listing all authors not just presenters. And feel free to get in touch with us. Josh Reiss (author of this blog entry), J. T. Colonel, and Angeliki Mourgela from the Audio Engineering research team within the Centre for Digital Music, will all be (virtually) there.
We try to write a preview of the technical track for almost all recent Audio Engineering Society (AES) Conventions, see our entries on the 142nd, 143rd, 144th, 145th and 147th Conventions. But this 148th Convention is very different.
It is, of course, an online event. The Convention planning committee have put huge effort into putting it all online and making it a really engaging and exciting experience (and in massively reducing costs). There will be a mix of live-streams, break out sessions, interactive chat rooms and so on. But the technical papers will mostly be on-demand viewing, with Q&A and online dialog with the authors. This is great in the sense that you can view it and interact with authors any time, but it means that its easy to overlook really interesting work.
So we’ve gathered together some information about a lot of the presented research that caught our eye as being unusual, exceptionally high quality, or just worth mentioning. And every paper mentioned here will appear soon in the AES E-Library, by the way. Currently though, you can browse all the abstracts by searching the full papers and engineering briefs on the Convention website.
Deep learning and neural networks are all the rage in machine learning nowadays. A few contributions to the field will be presented by Eugenio Donati with ‘Prediction of hearing loss through application of Deep Neural Network’, Simon Plain with ‘Pruning of an Audio Enhancing Deep Generative Neural Network’, Giovanni Pepe’s presentation of ‘Generative Adversarial Networks for Audio Equalization: an evaluation study’, Yiwen Wang presenting ‘Direction of arrival estimation based on transfer function learning using autoencoder network’, and the author of this post, Josh Reiss will present work done mainly by sound designer/researcher Guillermo Peters, ‘A deep learning approach to sound classification for film audio post-production’. Related to this, check out the Workshop on ‘Deep Learning for Audio Applications – Engineering Best Practices for Data’, run by Gabriele Bunkheila of MathWorks (Matlab), which will be live-streamed on Friday.
There’s enough work being presented on spatial audio that there could be a whole conference on the subject within the convention. A lot of that is in Keynotes, Workshops, Tutorials, and the Heyser Memorial Lecture by Francis Rumsey. But a few papers in the area really stood out for me. Toru Kamekawa’s investigated a big question with ‘Are full-range loudspeakers necessary for the top layer of 3D audio?’ Marcel Nophut’s ‘Multichannel Acoustic Echo Cancellation for Ambisonics-based Immersive Distributed Performances’ has me intrigued because I know a bit about echo cancellation and a bit about ambisonics, but have no idea how to do the former for the latter.
And I’m intrigued by ‘Creating virtual height loudspeakers using VHAP’, presented by Kacper Borzym. I’ve never heard of VHAP, but the original VBAP paper is the most highly cited paper in the Journal of the AES (1367 citations at the time of writing this).
How good are you at understanding speech from native speakers? How about when there’s a lot of noise in the background? Do you think you’re as good as a computer? Gain some insight into related research when viewing the presentation by Eugenio Donati on ‘Comparing speech identification under degraded acoustic conditions between native and non-native English speakers’.
There’s a few papers exploring creative works, all of which look interesting and have great titles. David Poirier-Quinot will present ‘Emily’s World: behind the scenes of a binaural synthesis production’. Music technology has a fascinating history. Michael J. Murphy will explore the beginning of a revolution with ‘Reimagining Robb: The Sound of the World’s First Sample-based Electronic Musical Instrument circa 1927’. And if you’re into Scandinavian instrumental rock music (and who isn’t?), Zachary Bresler’s presentation of ‘Music and Space: A case of live immersive music performance with the Norwegian post-rock band Spurv’ is a must.
Frank Morse Robb, inventor of the first sample-based electronic musical instrument.
But sound creation comes first, and new technologies are emerging to do it. Damian T. Dziwis will present ‘Body-controlled sound field manipulation as a performance practice’. And particularly relevant given the worldwide isolation going on is ‘Quality of Musicians’ Experience in Network Music Performance: A Subjective Evaluation,’ presented by Konstantinos Tsioutas.
Portraiture looks at how to represent or capture the essence and rich details of a person. Maree Sheehan explores how this is achieved sonically, focusing on Maori women, in an intriguing presentation on ‘Audio portraiture sound design- the development and creation of audio portraiture within immersive and binaural audio environments.’
We talked about exciting research on metamaterials for headphones and loudspeakers when giving previews of previous AES Conventions, and there’s another development in this area presented by Sebastien Degraeve in ‘Metamaterial Absorber for Loudspeaker Enclosures’
Paul Ferguson and colleagues look set to break some speed records, but any such feats require careful testing first, as in ‘Trans-Europe Express Audio: testing 1000 mile low-latency uncompressed audio between Edinburgh and Berlin using GPS-derived word clock’
Our own research has focused a lot on intelligent music production, and especially automatic mixing. A novel contribution to the field, and a fresh perspective, is given in Nyssim Lefford’s presentation of ‘Mixing with Intelligent Mixing Systems: Evolving Practices and Lessons from Computer Assisted Design’.
Subjective evaluation, usually in the form of listening tests, is the primary form of testing audio engineering theory and technology. As Feynman said, ‘if it disagrees with experiment, its wrong!’
And thus, there are quite a few top-notch research presentations focused on experiments with listeners. Minh Voong looks at an interesting aspect of bone conduction with ‘Influence of individual HRTF preference on localization accuracy – a comparison between regular and bone conducting headphones. Realistic reverb in games is incredibly challenging because characters are always moving, so Zoran Cvetkovic tackles this with ‘Perceptual Evaluation of Artificial Reverberation Methods for Computer Games.’ The abstract for Lawrence Pardoe’s ‘Investigating user interface preferences for controlling background-foreground balance on connected TVs’ suggests that there’s more than one answer to that preference question. That highlights the need for looking deep into any data, and not just considering the mean and standard deviation, which often leads to Simpson’s Paradox. And finally, Peter Critchell will present ‘A new approach to predicting listener’s preference based on acoustical parameters,’ which addresses the need to accurately simulate and understand listening test results.
The Constant-Q Transform represents a signal in frequency domain, but with logarithmically spaced bins. So potentially very useful for audio. The last decade has seen a couple of breakthroughs that may make it far more practical. I was sitting next to Gino Velasco when he won the “best student paper” award for Velasco et al.’s “Constructing an invertible constant-Q transform with nonstationary Gabor frames.” Schörkhuber and Klapuri also made excellent contributions, mainly around implementing a fast version of the transform, culminating in a JAES paper. and the teams collaborated together on a popular Matlab toolbox. Now there’s another advance with Felix Holzmüller presenting ‘Computational efficient real-time capable constant-Q spectrum analyzer’.
The abstract for Dan Turner’s ‘Content matching for sound generating objects within a visual scene using a computer vision approach’ suggests that it has implications for selection of sound effect samples in immersive sound design. But I’m a big fan of procedural audio, and think this could have even higher potential for sound synthesis and generative audio systems.
And finally, there’s some really interesting talks about innovative ways to conduct audio research based on practical challenges. Nils Meyer-Kahlen presents ‘DIY Modifications for Acoustically Transparent Headphones’. The abstract for Valerian Drack’s ‘A personal, 3D printable compact spherical loudspeaker array’, also mentions its use in a DIY approach. Joan La Roda’s own experience of festival shows led to his presentation of ‘Barrier Effect at Open-air Concerts, Part 1’. Another presentation with deep insights derived from personal experience is Fabio Kaiser’s ‘Working with room acoustics as a sound engineer using active acoustics.’ And the lecturers amongst us will be very interested in Sebastian Duran’s ‘Impact of room acoustics on perceived vocal fatigue of staff-members in Higher-education environments: a pilot study.’
Remember to check the AES E-Library which will soon have all the full papers for all the presentations mentioned here, including listing all authors not just presenters. And feel free to get in touch with us. Josh Reiss (author of this blog entry), J. T. Colonel, and Angeliki Mourgela from the Audio Engineering research team within the Centre for Digital Music, will all be (virtually) there.
We previewed the 142nd, 143rd, 144th and 145th Audio Engineering Society (AES) Conventions, which we also followed with wrap-up discussions. Then we took a break, but now we’re back to preview the 147th AES convention, October 16 to 19 in New York. As before, the Audio Engineering research team here aim to be quite active at the convention.
We’ve gathered together some information about a lot of the research-oriented events that caught our eye as being unusual, exceptionally high quality, involved in, attending, or just worth mentioning. And this Convention will certainly live up to the hype.
Wednesday October 16th
When I first read the title of the paper ‘Evaluation of Multichannel Audio in Automobiles versus Mobile Phones‘, presented at 10:30, I thought it was a comparison of multichannel automotive audio versus the tinny, quiet mono or barely stereo from a phone. But its actually comparing results of a listening test for stereo vs multichannel in a car, with results of a listening test for stereo vs multichannel for the same audio, but from a phone and rendered over headphones. And the results look quite interesting.
There’s so many deep learning papers, but the 3-4:30 poster ‘Modal Representations for Audio Deep Learning‘ stands out from the pack. Deep learning for audio most often works with raw spectrogram data. But this work proposes learning modal filterbank coefficients directly, and they find it gives strong results for classification and generative tasks. Also in that session, ‘Analysis of the Sound Emitted by Honey Bees in a Beehive‘ promises to be an interesting and unusual piece of work. We talked about their preliminary results in a previous entry, but now they’ve used some rigorous audio analysis to make deep and meaningful conclusions about bee behaviour.
Immerse yourself in the world of virtual and augmented reality audio technology today, with some amazing workshops, like Music Production in VR and AR, Interactive AR Audio Using Spark, Music Production in Immersive Formats, ISSP: Immersive Sound System Panning, and Real-time Mixing and Monitoring Best Practices for Virtual, Mixed, and Augmented Reality. See the Calendar for full details.
Just below, I mention the need for multitrack audio data sets. Closely related, and also much needed, is this work on ‘A Dataset of High-Quality Object-Based Productions‘, also in the 3:30-5 poster session.
Saturday, October 19th
We’re approaching a world where almost every surface can be a visual display. Imagine if every surface could be a loudspeaker too. Such is the potential of metamaterials, discussed in ‘Acoustic Metamaterial in Loudspeaker Systems Design‘ at 10:45.
I always appreciate filling the gaps in my knowledge. And though I know a lot about sound enhancement, I’ve never dived into how its done and how effective it is in soundbars, now widely used in home entertainment. So I’m looking forward to the poster ‘A Qualitative Investigation of Soundbar Theory‘, shown 10:30-12. From the title and abstract though, this feels like it might work better as an oral presentation. Also in that session, the poster ‘Sound Design and Reproduction Techniques for Co-Located Narrative VR Experiences‘ deserves special mention, since it won the Convention’s Best Peer-Reviewed Paper Award, and promises to be an important contribution to the growing field of immersive audio.
Its wonderful to see research make it into ‘product’, and ‘Casualty Accessible and Enhanced (A&E) Audio: Trialling Object-Based Accessible TV Audio‘, presented at 3:45, is a great example. Here, new technology to enhance broadcast audio for those with hearing loss iwas trialed for a popular BBC drama, Casualty. This is of extra interest to me since one of the researchers here, Angeliki Mourgela, does related research, also in collaboration with BBC. And one of my neighbours is an actress who appears on that TV show.
I encourage the project students working with me to aim for publishable research. Jorge Zuniga’s ‘Realistic Procedural Sound Synthesis of Bird Song Using Particle Swarm Optimization‘, presented at 2:30, is a stellar example. He created a machine learning system that uses bird sound recordings to find settings for a procedural audio model. Its a great improvement over other methods, and opens up a whole field of machine learning applied to sound synthesis.
At 3 o’clock in the same session is another paper from our team, Angeliki Mourgela presenting ‘Perceptually Motivated Hearing Loss Simulation for Audio Mixing Reference‘. Roughly 1 in 6 people suffer from some form of hearing loss, yet amazingly, sound engineers don’t know what the content will sound like to them. Wouldn’t it be great if the engineer could quickly audition any content as it would sound to hearing impaired listeners? That’s the aim of this research.
I became a professor last year, which is quite a big deal here. On April 17th, I gave my Inaugural lecture, which is a talk on my subject area to the general public. I tried to make it as interesting as possible, with sound effects, videos, a live experiment and even a bit of physical comedy. Here’s the video, and below I have a (sort of) transcript.
The Start
What did you just hear, what’s the weather like outside? Did that sound like a powerful, wet storm with rain, wind and thunder, or did it sound fake, was something not quite right? All you had was nearly identical, simple signals from each speaker, and you only received two simple, nearly identical signals, one to each ear. Yet somehow you were able to interpret all the rich details, know what it was and assess the quality.
Over the next hour or so, we’ll investigate the research that links deep understanding of sound and sound perception to wonderful new audio technologies. We’ll look at how market needs in the commercial world are addressed by basic scientific advances. We will explore fundamental challenges about how we interact with the auditory world around us, and see how this leads to new creative artworks and disruptive innovations.
Sound effect synthesis
But first, lets get back to the storm sounds you heard. Its an example of a sound effect, like what might be used in a film. Very few of the sounds that you hear in film or TV, and more and more frequently, in music too, are recorded live on set or on stage.
Such sounds are sometimes created by what is known as Foley, named after Jack Foley, a sound designer working in film and radio from the late 1920s all the way to the early 1960s. In its simplest form, Foley is basically banging pots and pans together and sticking a microphone next to it. It also involves building mechanical contraptions to create all sorts of sounds. Foley sound designers are true artists, but its not easy, its expensive and time consuming. And the Foley studio today looks almost exactly the same as it did 60 years ago. The biggest difference is that the photos of the Foley studios are now in colour.
But most sound effects come from sample libraries. These consist of tens or hundreds of thousands of high quality recordings. But they are still someone else’s vision of the sounds you might need. They’re never quite right. So sound designers either ‘make do’ with what’s there, or expend effort trying to shape them towards some desired sound. The designer doesn’t have the opportunity to do creative sound design. Reliance on pre-recorded sounds has dictated the workflow. The industry hasn’t evolved, we’re simply adapting old ways to new problems.
In contrast, digital video effects have reached a stunning level of realism, and they don’t rely on hundreds of thousands of stock photos, like the sound designers do with sample libraries. And animation is frequently created by specifying the scene and action to some rendering engine, without designers having to manipulate every little detail.
There might be opportunities for better and more creative sound design. Instead of a sound effect as a chunk of bits played out in sequence, conceptualise the sound generating mechanism, a procedure or recipe that when implemented, produces the desired sound. One can change the procedure slightly, shaping the sound. This is the idea behind sound synthesis. No samples need be stored. Instead, realistic and desired sounds can be generated from algorithms.
This has a lot of advantages. Synthesis can produce a whole range of sounds, like walking and running at any speed on any surface, whereas a sound effect library has only a finite number of predetermined samples. Synthesized sounds can play for any amount of time, but samples are fixed duration. Synthesis can have intuitive controls, like the enthusiasm of an applauding audience. And synthesis can create unreal or imaginary sounds that never existed in nature, a roaring dragon for instance, or Jedi knights fighting with light sabres..
Give this to sound designers, and they can take control, shape sounds to what they want. Working with samples is like buying microwave meals, cheap and easy, but they taste awful and there’s no satisfaction. Synthesis on the other hand, is like a home-cooked meal, you choose the ingredients and cook it the way you wish. Maybe you aren’t a fine chef, but there’s definitely satisfaction in knowing you made it.
This represents a disruptive innovation, changing the marketplace and changing how we do things. And it matters; not just to professional sound designers, but to amateurs and to the consumers, when they’re watching a film and especially, since we’re talking about sound, when they are listening to music, which we’ll come to later in the talk.
That’s the industry need, but there is some deep research required to address it. How do you synthesise sounds? They’re complex, with lots of nuances that we don’t fully understand. A few are easy, like these-
I just played that last one to get rid of the troublemakers in the audience.
But many of those are artificial or simple mechanical sounds. And the rest?
Almost no research is done in isolation, and there’s a community of researchers devising sound synthesis methods. Many approaches are intended for electronic music, going back to the work of Daphne Oram and Delia Derbyshire at the BBC Radiophonics Workshop, or the French Musique Concrete movement. But they don’t need a high level of realism. Speech synthesis is very advanced, but tailored for speech of course, and doesn’t apply to things like the sound of a slamming door. Other methods concentrate on simulating a particular sound with incredible accuracy. They construct a physical model of the whole system that creates the sound, and the sound is an almost incidental output of simulating the system. But this is very computational and inflexible.
And this is where we are today. The researchers are doing fantastic work on new methods to create sounds, but its not addressing the needs of sound designers.
Well, that’s not entirely true.
The games community has been interested in procedural audio for quite some time. Procedural audio embodies the idea of sound as a procedure, and involves looking at lightweight interactive sound synthesis models for use in a game. Start with some basic ingredients; noise, pulses, simple tones. Stir them together with the right amount of each, bake them with filters that bring out various pitches, add some spice and you start to get something that sounds like wind, or an engine or a hand clap. That’s the procedural audio approach.
A few tools have seen commercial use, but they’re specialised and integration of new technology in a game engine is extremely difficult. Such niche tools will supplement but not replace the sample libraries.
A few years ago, my research team demonstrated a sound synthesis model for engine and motor sounds. We showed that this simple software tool could be used by a sound designer to create a diverse range of sounds, and it could match those in the BBC sound effect library, everything from a handheld electric drill to a large boat motor.
This is the key. Designed right, one synthesis model can create a huge, diverse range of sounds. And this approach can be extended to simulate an entire effects library using only a small number of versatile models.
That’s what you’ve been hearing. Every sound sample you’ve heard in this talk was synthesised. Artificial sounds created and shaped in real-time. And they can be controlled and rendered in the same way that computer animation is performed. Watch this example, where the synthesized propeller sounds are driven by the scene in just the same way as the animation was.
It still needs work of course. You could hear lots of little mistakes, and the models missed details. And what we’ve achieved so far doesn’t scale. We can create hundred of sounds that one might want, but not yet thousands or tens of thousands.
But we know the way forward. We have a precious resource, the sound effect libraries themselves. Vast quantities of high quality recordings, tried and tested over decades. We can feed these into machine learning systems to uncover the features associated with every type of sound effect, and then train our models to find settings that match recorded samples.
We can go further, and use this approach to learn about sound itself. What makes a rain storm sound different from a shower? Is there something in common with all sounds that startle us, or all sounds that calm us? The same approach that hands creativity back to sound designers, resulting in wonderful new sonic experiences, can also tell us so much about sound perception.
Hot versus cold
I pause, say “I’m thirsty”. I have an empty jug and pretend to pour
Pretend to throw it at the audience.
Just kidding. That’s another synthesised sound. It’s a good example of this hidden richness in sounds. You knew it was pouring because the gesture helped, and there is an interesting interplay between our visual and auditory senses. You also heard bubbles, splashes, the ring of the container that its poured into. But do you hear more?
I’m going to run a little experiment. I have two sound samples, hot water being poured and cold water being poured. I want you to guess which is which.
I think its fascinating that we can hear temperature. There must be some physical phenomenon affecting the sound, which we’ve learned to associate with heat. But what’s really interesting is what I found when I looked online. Lots of people have discussed this. One argument goes ‘Cold water is more viscuous or sticky, and so it gives high pitched sticky splashes.’ That makes sense. But another argument states ‘There are more bubbles in a hot liquid, and they produce high frequency sounds.’
Wait, they can’t both be right. So we analysed recordings of hot and cold water being poured, and it turns out they’re both wrong! The same tones are there in both recordings, so essentially the same pitch. But the strengths of the tones are subtly different. Some sonic aspect is always present, but its loudness is a function of temperature. We’re currently doing analysis to find out why.
And no one noticed! In all the discussion, no one bothered to do a little critical analysis or an experiment. It’s an example of a faulty assumption, that because you can come up with a solution that makes sense, it should be the right one. And it demonstrates the scientific method; nothing is known until it is tested and confirmed, repeatedly.
Intelligent Music Production
Its amazing what such subtle changes can do, how they can indicate elements that one never associates with hearing. Audio production thrives on such subtle changes and there is a rich tradition of manipulating them to great effect. Music is created not just by the composer and performers. The sound engineer mixes and edits it towards some artistic vision. But phrasing the work of a mixing engineer as an art form is a double-edged sword, we aren’t doing justice to the technical challenges. The sound engineer is after all, an engineer.
In audio production, whether for broadcast, live sound, games, film or music, one typically has many sources. They each need to be heard simultaneously, but can all be created in different ways, in different environments and with different attributes. Some may mask each other, some may be too loud or too quiet. The final mix should have all sources sound distinct yet contribute to a nice clean blend of the sounds. To achieve this is very labour intensive and requires a professional engineer. Modern audio production systems help, but they’re incredibly complex and all require manual manipulation. As technology has grown, it has become more functional but not simpler for the user.
In contrast, image and video processing has become automated. The modern digital camera comes with a wide range of intelligent features to assist the user; face, scene and motion detection, autofocus and red eye removal. Yet an audio recording or editing device has none of this. It is essentially deaf; it doesn’t listen to the incoming audio and has no knowledge of the sound scene or of its intended use. There is no autofocus for audio!
Instead, the user is forced to accept poor sound quality or do a significant amount of manual editing.
But perhaps intelligent systems could analyse all the incoming signals and determine how they should be modified and combined. This has the potential to revolutionise music production, in effect putting a robot sound engineer inside every recording device, mixing console or audio workstation. Could this be achieved? This question gets to the heart of what is art and what is science, what is the role of the music producer and why we prefer one mix over another.
But unlike replacing sound effect libraries, this is not a big data problem. Ideally, we would get lots of raw recordings and the produced content that results. Then extract features from each track and the final mix in order to establish rules for how audio should be mixed. But we don’t have the data. Its not difficult to access produced content. But the initial multitrack recordings are some of the most highly guarded copyright material. This is the content that recording companies can use over and over, to create remixes and remastered versions. Even if we had the data, we don’t know the features to use and we don’t know how to manipulate those features to create a good mix. And mixing is a skilled craft. Machine learning systems are still flawed if they don’t use expert knowledge.
There’s a myth that as long as we get enough data, we can solve almost any problem. But lots of problems can’t be tackled this way. I thought weather prediction was done by taking all today’s measurements of temperature, humidity, wind speed, pressure… Then tomorrow’s weather could be guessed by seeing what happened the day after there were similar conditions in the past. But a meteorologist told me that’s not how it works. Even with all the data we have, its not enough. So instead we have a weather model, based on how clouds interact, how pressure fronts collide, why hurricanes form, and so on. We’re always running this physical model, and just tweaking parameters and refining the model as new data comes in. This is far more accurate than relying on mining big data.
You might think this would involve traditional signal processing, established techniques to remove noise or interference in recordings. Its true that some of what the sound engineer does is correct artifacts due to issues in the recording process. And there are techniques like echo cancellation, source separation and noise reduction that can address this. But this is only a niche part of what the sound engineer does, and even then the techniques have rarely been optimised for real world applications.
There’s also multichannel signal processing, where one usually attempts to extract information regarding signals that were mixed together, like acquiring a GPS signal buried in noise. But in our case, we’re concerned with how to mix the sources together in the first place. This opens up a new field which involves creating ways to manipulate signals to achieve a desired output. We need to identify multitrack audio features, related to the relationships between musical signals, and develop audio effects where the processing on any sound is dependent on the other sounds in the mix.
And there is little understanding of how we perceive audio mixes. Almost all studies have been restricted to lab conditions; like measuring the perceived level of a tone in the presence of background noise. This tells us very little about real world cases. It doesn’t say how well one can hear lead vocals when there are guitar, bass and drums.
Finally, best practices are not understood. We don’t know what makes a good mix and why one production will sound dull while another makes you laugh and cry, even though both are on the same piece of music, performed by competent sound engineers. So we need to establish what is good production, how to translate it into rules and exploit it within algorithms. We need to step back and explore more fundamental questions, filling gaps in our understanding of production and perception. We don’t know where the rules will be found, so multiple approaches need to be taken.
The first approach is one of the earliest machine learning methods, knowledge engineering. Its so old school that its gone out of fashion. It assumes experts have already figured things out, they are experts after all. So lets look at the sound engineering literature and work with experts to formalise their approach. Capture best practices as a set of rules and processes. But this is no easy task. Most sound engineers don’t know what they did. Ask a famous producer what he or she did on a hit song and you often get an answer like ‘I turned the knob up to 11 to make it sound phat.” How do you turn that into a mathematical equation? Or worse, they say it was magic and can’t be put into words.
To give you an idea, we had a technique to prevent acoustic feedback, that high pitched squeal you sometimes hear when a singer first approaches a microphone. We thought we had captured techniques that sound engineers often use, and turned it into an algorithm. To verify this, I was talking to an experienced live sound engineer and asked when was the last time he had feedback at one of the gigs where he ran the sound. ‘Oh, that never happens for me,’ he said. That seemed strange. I knew it was a common problem. ‘Really, never ever?’ ‘No, I know what I’m doing. It doesn’t happen.’ ‘Not even once?’ ‘Hmm, maybe once but its extremely rare.’ ‘Tell me about it.’ ‘Well, it was at the show I did last night…’! See, it’s a tricky situation. The sound engineer does have invaluable knowledge, but also has to protect their reputation as being one of a select few that know the secrets of the trade.
So we’re working with domain experts, generating hypotheses and formulating theories. We’ve been systematically testing all the assumptions about best practices and supplementing them with lots of listening tests. These studies help us understand how people perceive complex sound mixtures and identify attributes necessary for a good sounding mix. And we know the data will help. So we’re also curating multitrack audio, with detailed information about how it was recorded, often with multiple mixes and evaluations of those mixes.
By combining these approaches, my team have developed intelligent systems that automate much of the audio and music production process. Prototypes analyse all incoming sounds and manipulate them in much the same way a professional operates the controls at a mixing desk.
I didn’t realise at first the importance of this research. But I remember giving a talk once at a convention in a room that had panel windows all around. The academic talks are usually half full. But this time it was packed, and I could see faces outside all pressed up against the windows. They all wanted to find out about this idea of automatic mixing. Its a unique opportunity for academic research to have transformational impact on an entire industry. It addresses the fact that music production technologies are often not fit for purpose. Intelligent mixing systems automate the technical and mundane, allowing sound engineers to work more productively and creatively, opening up new opportunities. Audio quality could be improved, amateur musicians can create high quality mixes of their content, small venues can put on live events without needing a professional engineer, time and preparation for soundchecks could be drastically reduced, and large venues and broadcasters could significantly cut manpower costs.
Its controversial. We once entered an automatic mix in a student recording competition as a sort of Turing Test. Technically, we were cheating, because all the mixes were supposed to be made by students, but in our case it was made by an ‘artificial intelligence’ created by a student. We didn’t win of course, but afterwards I asked the judges what they thought of the mix, and then told them how it was done. The first two were surprised and curious when I told them how it was done. But the third judge offered useful comments when he thought it was a student mix. But when I told him that it was an ‘automatic mix’, he suddenly switched and said it was rubbish and he could tell all along.
Mixing is a creative process where stylistic decisions are made. Is this taking away creativity, is it taking away jobs? Will it result in music sounding more the same? Such questions come up time and time again with new technologies, going back to 19th century protests by the Luddites, textile workers who feared that time spent on their skills and craft would be wasted as machines could replace their role in industry.
These are valid concerns, but its important to see other perspectives. A tremendous amount of audio production work is technical, and audio quality would be improved by addressing these problems. As the graffiti artist Banksy said;
“All artists are willing to suffer for their work. But why are so few prepared to learn to draw?” – BaNKSY
Creativity still requires technical skills. To achieve something wonderful when mixing music, you first have to achieve something pretty good and address issues with masking, microphone placement, level balancing and so on.
The real benefit is not replacing sound engineers. Its dealing with all those situations when a talented engineer is not available; the band practicing in the garage, the small pub or restaurant venue that does not provide any support, or game audio, where dozens of incoming sounds need to be mixed and there is no miniature sound guy living inside the games console.
High resolution audio
The history of audio production is one of continual innovation. New technologies arise to make the work easier, but artists also figure out how to use that technology in new creative ways. And the artistry is not the only element music producers care about. They’re interested, some would say obsessed, with fidelity. They want the music consumed at home to be as close as possible to the experience of hearing it live. But we consume digitial audio. Sound waves are transformed into bits and then transformed back to sound when we listen. We sample sound many times a second and render each sample with so many bits. Luckily, there is a very established theory on how to do the sampling.
We only hear frequencies up to about 20 kHz. That’s a wave which repeats 20,000 times a second. There’s a famous theorem by Claude Shannon and Harry Nyquist which states that you need twice that number of samples a second to fully represent a signal up to 20 kHz, so sample at 40,000 samples a second, or 40 kHz. So the standard music format, 16 bit samples and 44.1 kHz sampling rate, should be good enough.
But most music producers want to work with higher quality formats and audio companies make equipment for recording and playing back audio in these high resolution formats. Some people swear they hear a difference, others say it’s a myth and people are fooling themselves. What’s going on? Is the sampling theorem, which underpins all signal processing, fundamentally wrong? Have we underestimated the ability of our own ears and in which case the whole field of audiology is flawed? Or could it be that the music producers and audiophiles, many of whom are renowned for their knowledge and artistry, are deluded?
Around the time I was wondering about this, I went to a dinner party and was sat across from a PhD student. His PhD was in meta-analysis, and he explained that it was when you gather all the data from previous studies on a question and do formal statistical analysis to come up with more definitive results than the original studies. It’s a major research method in evidence-based medicine, and every few weeks a meta-analysis makes headlines because it shows the effectiveness or lack of effectiveness of treatments.
So I set out to do a meta-analysis. I tried to find every study that ever looked at perception of high resolution audio, and get their data. I scoured every place they could have been published and asked everyone in the field, all around the world. One author literally found his old data tucked away in the back of a filing cabinet. Another couldn’t get permission to provide the raw data, but told me enough about it for me to write a little program that ran through all possible results until it found the details that would reproduce the summary data as well. In the end, I found 18 relevant studies and could get data from all of them except one. That was strange, since it was the most famous study. But the authors had ‘lost’ the data, and got angry with me when I asked them for details about the experiment.
The results of the meta-analysis were fascinating, and not at all what I expected. There were researchers who thought their data had or hadn’t shown an effect, but when you apply formal analysis, it’s the opposite. And a few experiments had major flaws. For instance, in one experiment many of the high resolution recordings were actually standard quality, which means there never was a difference to be perceived. In another, test subjects were given many versions of the same audio, including a direct live feed, and asked which sounds closer to live. People actually ranked the live feed as sounding least close to live, indicating they just didn’t know what to listen for.
As for the one study where the authors lost their data? Well, they had published some of it, but it basically went like this. 55 participants listened to many recordings many times and could not discriminate between high resolution and standard formats. But men discriminated more than women, older far more than younger listeners, audiophiles far more than nonexperts. Yet only 3 people ever guessed right more than 6 times out of 10. The chance of all this happening by luck if there really was no difference is less likely than winning the lottery. Its extremely unlikely even if there was a difference to be heard. Conclusion: they faked their data.
And this was the study which gave the most evidence that people couldn’t hear anything extra in high resolution recordings. In fact the studies with the most flaws were those that didn’t show an effect. Those that found an effect were generally more rigourous and took extra care in their design, set-up and analysis. This was counterintuitive. People are always looking for a new cure or a new effect. But in this case, there was a bias towards not finding a result. It seems researchers wanted to show that the claims of hearing a difference are false.
The biggest factor was training. Studies where subjects, even those experienced working with audio, just came in and were asked to state when two versions of a song were the same, rarely performed better than chance. But if they were told what to listen for, given examples, were told when they got it right or wrong, and then came back and did it under blind controlled conditions, they performed far better. All studies where participants were given training gave higher results than all studies where there was no training. So it seems we can hear a difference between standard and high resolution formats, we just don’t know what to listen for. We listen to music everyday, but we do it passively and rarely focus on recording quality. We don’t sit around listening for subtle differences in formats, but they are there and they can be perceived. To audiophiles, that’s a big deal.
In 2016 I published this meta-analysis in the Journal of the Audio Engineering Society, and it created a big splash. I had a lot of interviews in the press, and it was discussed on social media and internet forums. And that’s when I found out, people on the internet are crazy! I was accused of being a liar, a fraud, paid by the audio industry, writing press releases, working the system and pushing an agenda. These criticisms came from all sides, since differences were found which some didn’t think existed, but they also weren’t as strong as others wanted them to be. I was also accused of cherry-picking the studies, even though one of the goals of the paper was to avoid exactly that, which is why I included every study I could find.
But my favorite comment was when someone called me an ‘intellectually dishonest placebophile apologist’. Whoever wrote that clearly spent time and effort coming up with a convoluted insult.
It wasn’t just people online who were crazy. At an audio engineering society convention, two people were discussing the paper. One was a multi-grammy award winning mixing engineer and inventor, the other had a distinguished career as chief scientist at a major audio company.
What started as discussion escalated to heated argument, then shouting, then pushing and shoving. It was finally broken up when a famous mastering engineer intervened. I guess I should be proud of this.
I learned what most people already know, how very hard it is to change people’s minds once an opinion has been formed. And people rarely look at the source. Instead, they rely on biased opinions discussing that source. But for those interested in the issue whose minds were not already made up, I think the paper was useful.
I’m trying to figure out why we hear this difference. Its not due to problems with the high resolution audio equipment, that was checked in every study that found a difference. There’s no evidence that people have super hearing or that the sampling theorem is violated. But we need to remove all the high frequencies in a signal before we convert it to digital, even if we don’t hear them. That brings up another famous theorem, the uncertainty principle. In quantum mechanics, it tells us that we can’t resolve a particle’s position and momentum at the same time. In signal processing, it tells us that restricting a signal’s frequency content will make us less certain about its temporal aspects. When we remove those inaudible high frequencies, we smear out the signal. It’s a small effect, but this spreading the sound a tiny bit may be audible.
The End
The sounds around us shape our perception of the world. We saw that in films, games, music and virtual reality, we recreate those sounds or create unreal sounds to evoke emotions and capture the imagination. But there is a world of fascinating phenomena related to sound and perception that is not yet understood. Can we create an auditory reality without relying on recorded samples? Could a robot replace the sound engineer, should it? Investigating such questions has led to a deeper understanding of auditory perception, and has the potential to revolutionise sound design and music production.
What are the limits of human hearing? Do we make far greater use of auditory information than simple models can account for? And if so, can we feed this back for better audio production and sound design?
To answer these questions, we need to look at the human auditory system. Sound waves are transferred to the inner ear, which contains one of the most amazing organs in the human body, the cochlea. 3,500 inner hair cells line the cochlea, and resonate in response to frequencies across the audible range. These hair cells connect to a nerve string containing 30,000 neurons which can fire 600 pulses a second. So the brainstem receives up to 18 million pulses per second. Hence the cochlea is a very high resolution frequency analyser with digital outputs. Audio engineers would pay good money for that sort of thing, and we have two of them, free, inside our heads!
The pulses carry frequency and temporal information about sounds. This is sent to the brain’s auditory cortex, where hearing sensations are stored as aural activity images. They’re compared with previous aural activity images, other sensory images and overall context to get an aural scene representing the meaning of hearing sensations. This scene is made available to other processes in the brain, including thought processes such as audio assessment. It’s all part of 100 billion brain cells with 500 trillion connections, a massively powerful machine to manage body functions, memory and thinking.
These connections can be rewired based on experiences and stimuli. We have the power to learn new ways to process sounds. The perception is up to us. Like we saw with hot and cold water sounds, with perception of sound effects and music production, with high resolution audio, we have the power to train ourselves to perceive the subtlest aspects. Nothing is stopping us from shaping and appreciating a better auditory world.
The Ig Nobel prizes are tongue-in-cheek awards given every year to celebrate unusual or trivial achievements in science. Named as a play on the Nobel prize and the word ignoble, they are intended to ‘“honor achievements that first make people laugh, and then make them think.” Previously, when discussing graphene-based headphones graphene-based headphones, I mentioned Andre Geim, the only scientist to have won both a Nobel and Ig Nobel prize.
I only recently noticed that the 2017 Ig Nobel Peace Prize went to an international team that demonstrated that playing a didgeridoo is an effective treatment for obstructive sleep apnoea and snoring. Here’s a photo of one of the authors of the study playing the didge at the award ceremony.
But lets return to Digeridoo research. Its a fascinating aboriginal Australian instrument, with a rich history and interesting acoustics, and produces an eerie drone-like sound.
A search on google scholar, once removing patents and citations, shows only 38 research papers with Didgeridoo in the title. That’s great news if you want to be an expert on research in the subject. The work of Neville H. Fletcher over about a thirty year period beginning in the early 1980s is probably the main starting point.
The passive acoustics of the didgeridoo are well understood. Its a long truncated conical horn where the player’s lips at the smaller end form a pressure-controlled valve. Knowing the length and diameters involved, its not to difficult to determine the fundamental frequencies (often around 50-100 Hz) and modes excited, and their strengths, in much the same way as can be done for many woodwind instruments.
But that’s just the passive acoustics. Fletcher pointed out that traditional, solo didgeridoo players don’t pay much attention to the resonant frequencies and they’re mainly important when its played in Western music, and needs to fit with the rest of an ensemble.
Things start getting really interesting when one considers the sounding mechanism. Players make heavy use of circular breathing, breathing in through the nose while breathing out through the mouth, even more so, and more rhythmically, than is typical in performing Western brass instruments like trumpets and tubas. Changes in lip motion and vocal tract shape are then used to control the formants, allowing the manipulation of very rich timbres.
Its these aspects of didgeridoo playing that intrigued the authors of the sleep apnoea study. Like the DFA and cough drop wrapper studies mentioned above, these were serious studies on a seemingly not so serious subject. Circular breathing and training of respiratory muscles may go a long way towards improving nighttime breathing, and hence reducing snoring and sleep disturbances. The study was controlled and randomised. But, its incredibly difficult in these sorts of studies to eliminate or control for all the other variables, and very hard to identify which aspect of the didgeridoo playing was responsible for the better sleep. The authors quite rightly highlighted what I think is one of the biggest question marks in the study;
A limitation is that those in the control group were simply put on a waiting list because a sham intervention for didgeridoo playing would be difficult. A control intervention such as playing a recorder would have been an option, but we would not be able to exclude effects on the upper airways and compliance might be poor.
In that respect, drug trials are somewhat easier to interpret than practice-based intervention. But the effect was abundantly clear and quite strong. One certainly should not dismiss the results because of limitations (the limitations give rise to question marks, but they’re not mistakes) in the study.