About five months ago, we previewed the last European Audio Engineering Society Convention, which we followed with a wrap-up discussion. The next AES convention is just around the corner, October 18 to 21st in New York. As before, the Audio Engineering research team here aim to be quite active at the convention.
These conventions are quite big, with thousands of attendees, but not so large that you get lost or overwhelmed. Away from the main exhibition hall is the Technical Program, which includes plenty of tutorials and presentations on cutting edge research.
So here, we’ve gathered together some information about a lot of the events that we will be involved in, attending, or we just thought were worth mentioning. And I’ve gotta say, the Technical Program looks amazing.
Wednesday
One of the first events of the Convention is the Diversity Town Hall, which introduces the AES Diversity and Inclusion Committee. I’m a firm supporter of this, and wrote a recent blog entry about female pioneers in audio engineering. The AES aims to be fully inclusive, open and encouraging to all, but that’s not yet fully reflected in its activities and membership. So expect to see some exciting initiatives in this area coming soon.
In the 10:45 to 12:15 poster session, Steve Fenton will present Alternative Weighting Filters for Multi-Track Program Loudness Measurement. We’ve published a couple of papers (Loudness Measurement of Multitrack Audio Content Using Modifications of ITU-R BS.1770, and Partial loudness in multitrack mixing) showing that well-known loudness measures don’t correlate very well with perception when used on individual tracks within a multitrack mix, so it would be interesting to see what Steve and his co-author Hyunkook Lee found out. Perhaps all this research will lead to better loudness models and measures.
At 2 pm, Cleopatra Pike will present a discussion and analysis of Direct and Indirect Listening Test Methods. I’m often sceptical when someone draws strong conclusions from indirect methods like measuring EEGs and reaction times, so I’m curious what this study found and what recommendations they propose.
The 2:15 to 3:45 poster session will feature the work with probably the coolest name, Influence of Audience Noises on the Classical Music Perception on the Example of Anti-cough Candies Unwrapping Noise. And yes, it looks like a rigorous study, using an anechoic chamber to record the sounds of sweets being unwrapped, and the signal analysis is coupled with a survey to identify the most distracting sounds. It reminds me of the DFA faders paper from the last convention.
At 4:30, researchers from Fraunhofer and the Technical University of Ilmenau present Training on the Acoustical Identification of the Listening Position in a Virtual Environment. In a recent paper in the Journal of the AES, we found that training resulted in a huge difference between participant results in a discrimination task, yet listening tests often employ untrained listeners. This suggests that maybe we can hear a lot more than what studies suggest, we just don’t know how to listen and what to listen for.
Thursday
If you were to spend only one day this year immersing yourself in frontier audio engineering research, this is the day to do it.
At 9 am, researchers from Harman will present part 1 of A Statistical Model that Predicts Listeners’ Preference Ratings of In-Ear Headphones. This was a massive study involving 30 headphone models and 71 listeners under carefully controlled conditions. Part 2, on Friday, focuses on development and validation of the model based on the listening tests. I’m looking forward to both, but puzzled as to why they weren’t put back-to-back in the schedule.
At 10 am, researchers from the Tokyo University of the Arts will present Frequency Bands Distribution for Virtual Source Widening in Binaural Synthesis, a technique which seems closely related to work we presented previously on Cross-adaptive Dynamic Spectral Panning.
From 10:45 to 12:15, our own Brecht De Man will be chairing and speaking in a Workshop on ‘New Developments in Listening Test Design.’ He’s quite a leader in this field, and has developed some great software that makes the set up, running and analysis of listening tests much simpler and still rigorous.
In the 11-12:30 poster session, Nick Jillings will present Automatic Masking Reduction in Balance Mixes Using Evolutionary Computing, which deals with a challenging problem in music production, and builds on the large amount of research we’ve done on Automatic Mixing.
At 11:45, researchers from McGill will present work on Simultaneous Audio Capture at Multiple Sample Rates and Formats. This helps address one of the challenges in perceptual evaluation of high resolution audio (and see the open access journal paper on this), ensuring that the same audio is used for different versions of the stimuli, with only variation in formats.
At 1:30, renowned audio researcher John Vanderkooy will present research on how a loudspeaker can be used as the sensor for a high-performance infrasound microphone. In the same session at 2:30, researchers from Plextek will show how consumer headphones can be augmented to automatically perform hearing assessments. Should we expect a new audiometry product from them soon?
At 2 pm, our own Marco Martinez Ramirez will present Analysis and Prediction of the Audio Feature Space when Mixing Raw Recordings into Individual Stems, which applies machine learning to challenging music production problems. Immediately following this, Stephen Roessner discusses a Tempo Analysis of Billboard #1 Songs from 1955–2015, which builds partly on other work analysing hit songs to observe trends in music and production tastes.
At 3:45, there is a short talk on Evolving the Audio Equalizer. Audio equalization is a topic on which we’ve done quite a lot of research (see our review article, and a blog entry on the history of EQ). I’m not sure where the novelty is in the author’s approach though, since dynamic EQ has been around for a while, and there are plenty of harmonic processing tools.
At 4:15, there’s a presentation on Designing Sound and Creating Soundscapes for Still Images, an interesting and unusual bit of sound design.
Friday
Judging from the abstract, the short Tutorial on the Audibility of Loudspeaker Distortion at Bass Frequencies at 5:30 looks like it will be an excellent and easy to understand review, covering practice and theory, perception and metrics. In 15 minutes, I suppose it can only give a taster of what’s in the paper.
There’s a great session on perception from 1:30 to 4. At 2, perceptual evaluation expert Nick Zacharov gives a Comparison of Hedonic and Quality Rating Scales for Perceptual Evaluation. I think people often have a favorite evaluation method without knowing if its the best one for the test. We briefly looked at pairwise versus multistimuli tests in previous work, but it looks like Nick’s work is far more focused on comparing methodologies.
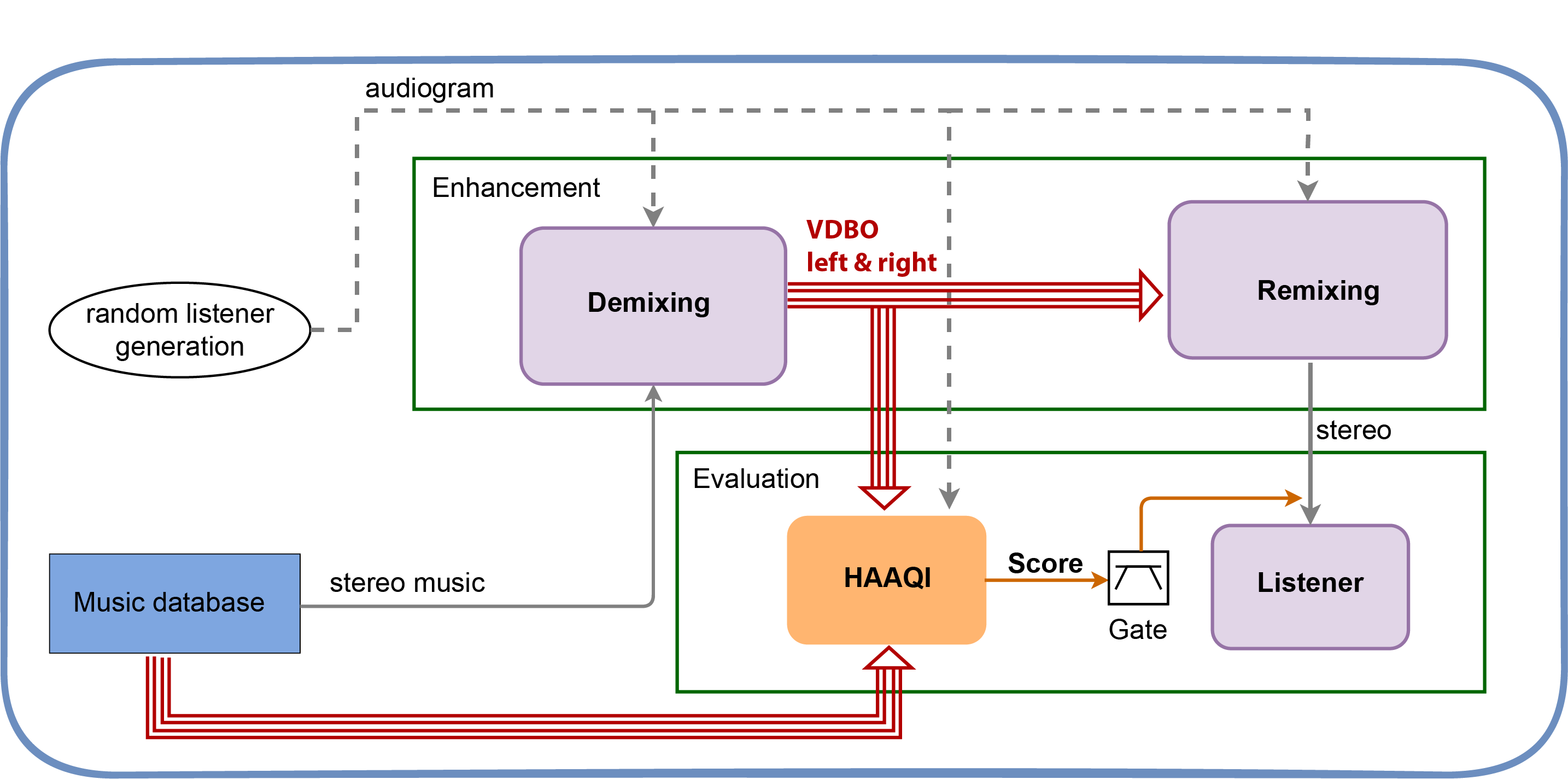
Immediately after that, researchers from the University of Surrey present Perceptual Evaluation of Source Separation for Remixing Music. Techniques for remixing audio via source separation is a hot topic, with lots of applications whenever the original unmixed sources are unavailable. This work will get to the heart of which approaches sound best.
The last talk in the session, at 3:30 is on The Bandwidth of Human Perception and its Implications for Pro Audio. Judging from the abstract, this is a big picture, almost philosophical discussion about what and how we hear, but with some definitive conclusions and proposals that could be useful for psychoacoustics researchers.
Saturday
Grateful Dead fans will want to check out Bridging Fan Communities and Facilitating Access to Music Archives through Semantic Audio Applications in the 9 to 10:30 poster session, which is all about an application providing wonderful new experiences for interacting with the huge archives of live Grateful Dead performances.
At 11 o’clock, Alessia Milo, a researcher in our team with a background in architecture, will discuss Soundwalk Exploration with a Textile Sonic Map. We discussed her work in a recent blog entry on Aural Fabric.
In the 2 to 3:30 poster session, I really hope there will be a live demonstration accompanying the paper on Acoustic Levitation.
At 3 o’clock, Gopal Mathur will present an Active Acoustic Meta Material Loudspeaker System. Metamaterials are receiving a lot of deserved attention, and such advances in materials are expected to lead to innovative and superior headphones and loudspeakers in the near future.
The full program can be explored on the Convention Calendar or the Convention website. Come say hi to us if you’re there! Josh Reiss (author of this blog entry), Brecht De Man, Marco Martinez and Alessia Milo from the Audio Engineering research team within the Centre for Digital Music will all be there.