Musings about music production, psychoacoustics, sound synthesis and anything else we find interesting, from the Centre for Digital Music's Audio Engineering research team.
The Intelligent Sound Engineering team (the people behind this blog) are part of the prestigious Centre for Digital Music (C4DM) at Queen Mary University of London. And we are pleased to announce that we have another R&D position opening up, related to machine learning and audio production. This position is for a collaborative project with a fast-growing London-based start-up in the music production sector. The position can be offered for either a post-doctoral or graduate research assistant, and can be either full- or part-time, and there is some flexibility in terms of salary and other aspects. Closing date for applications is May 1 2024.
About the Role: The School of Electronic Engineering and Computer Science at Queen Mary University of London is looking to recruit a part-time Research Assistant for the project Music Production Style Transfer (ProStyle). The role is to investigate machine learning approaches by which a production style may be learnt from examples and mapped onto new musical audio content. The work will build on prior work in this area, but the Research Assistant will be encouraged to explore new approaches.
About You: Applicants must hold a Master’s Degree (or equivalent) in Computer Science, Electrical/Electronic Engineering or a related field. They should have expertise in audio processing, audio programming, music production and machine learning, especially deep learning. It would also be desirable for applicants to have publications in leading journals in the field.
Signal processing challenges to rework music for those with a hearing loss
Intelligent sound engineering opens up the possibility of personalizing audio, for example processing and mixing music so the audio quality is better for someone with a hearing loss. People with a hearing impairment can experience problems when listening to music with or without hearing aids. 430 million people Worldwide have a disabling hearing loss, with this number increasing as the population ages. Poor hearing makes music harder to appreciate, for example picking out the lyrics or melody is more difficult. This reduces the enjoyment of music, and can lead to disengagement from listening and music-making.
I work on the Cadenza project, which has just launched a series of open competitions to get experts in music signal processing and machine learning to develop algorithms to improve music for those with a hearing loss. Such open challenges are increasingly used to push forward audio processing. They’re free to enter, and we provide lots of data, software and support to help competitors take part.
The Cadenza Challenges are about improving the perceived audio quality of recorded music for people with a hearing loss.
What do we mean by audio quality? Imagine listening to the same music track in two different ways. First on a low quality mp3 played on a cheap mobile, and then via a high quality wav and studio-grade monitors. The underlying music is the same in both cases, but the audio quality is very different.
Headphones
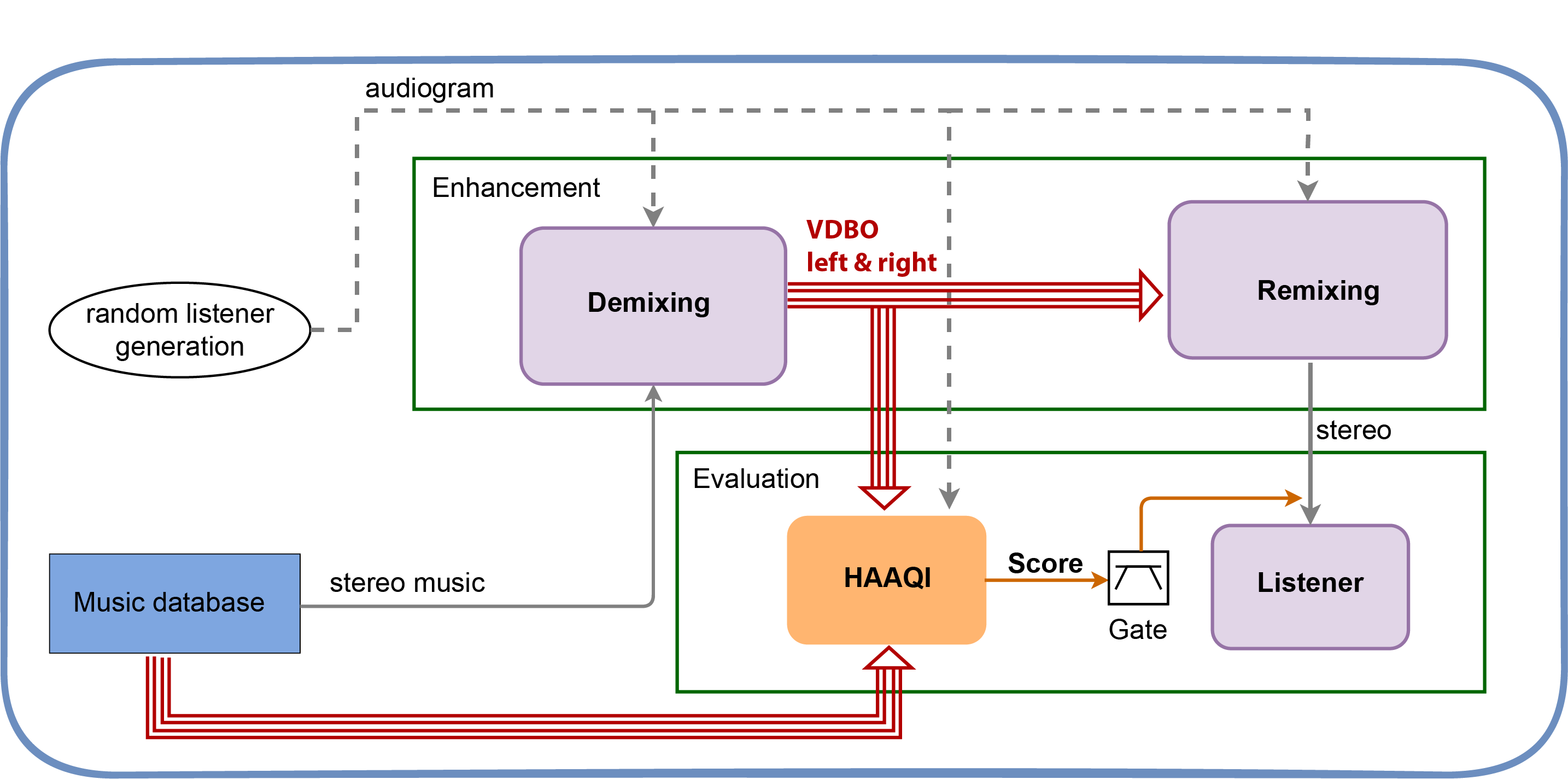
The first task you might tackle is our Task 1: listening over headphones. The figure below shows the software baseline that we are providing for you to build on. First the stereo music is demixed into VDBO (Vocals, Drums, Bass, Other) before being remixed into stereo for the listener to hear. At the remixing stage there is an opportunity for intelligent sound engineering to process the VDBO tracks and adjust the balance between them, to personalise and improve the music. We’re also hoping for improved demixing algorithms that allow for the hearing abilities of the listeners.
Car
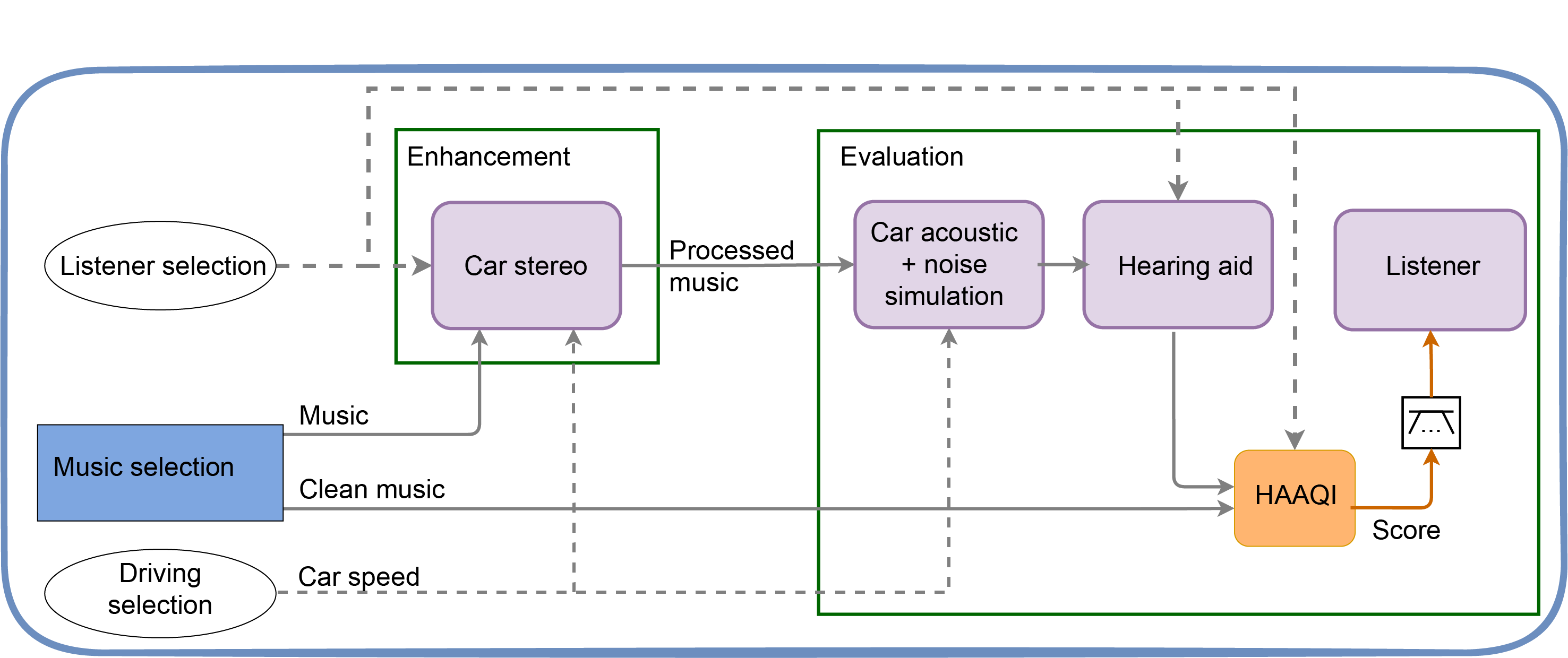
The second task you could tackle is intelligent sound engineering in the presence of noise. Listening to music in the car against the rumble of car noise is really common. How would you tune a car stereo (Enhancement box in the diagram below), so the processed music is best allowing for both the noise and the simple hearing aid the driver is wearing?
Next steps
Both tasks are live now, with entrants having to finish and submit their entries in July 2023. Join us in trying to improve music for those with a hearing loss. Or let us know what you think below, e.g., what do you think of the project idea and the scenarios we’ve chosen.
You’ll find lots more on the Cadenza project website, including a Learning Resources section that gives you background information on hearing, hearing loss, hearing aids and other knowledge you might need to enter the challenge. We also have a “find a team” page, if you want to get together with other experts to improve music for those with a hearing loss.
So its been a while since I’ve written a blog post. Life, work, and more work has made my time limited. But hopefully I’ll write more frequently in future.
The good news is that we have several fully funded PhD studentships which you or others you know might be interested in. They are all fully-funded, based at Queen Mary University of London, and starting September 2023.
With the exception of the last one, these are all 4 year studentships; the last one is for 3 years. Funding includes both a full tuition fee waiver and living stipend.
You’ll notice that there are related topics regarding machine learning applied to constructing simulations. This is an area where we have a strong interest, and there is scope for different projects pursuing different directions.
All the studentships are highly competitive, so its worth putting in a very strong application. And for those who fulfill CSC funding requirements or those who fulfill UK residency requirements, I recommend going for the last two, which may not be as competitive as the others. You can apply for more than one though.
If you or anyone you know is interested, please consider applying and feel free to ask me any questions. Good luck!
Adaptive footsteps plug-in released for Unreal and Unity game engines
From the creeping, ominous footsteps in a horror film to the thud clunk of an armored soldier in an action game, footstep sounds are one of the most widely souht after sound effects in creative content. But to get realistic variation, one needs hundreds of different samples for each character, each foot, each surface, and at different paces. Even then, repetition becomes a problem.
So at nemisindo.com , we’ve developed a procedural model for generating footstep sounds without the use of recorded samples. We’ve released it as the Nemisindo Adaptive Footsteps plug-in for game engines, available in the Unity Asset Store and in the Unreal Marketplace. You can also try it out at https://nemisindo.com/models/footsteps.html . It offers a lot more than standard sample packs libraries: footsteps are generated in real-time, based on intuitive parameters that you can control.
The plugin provides benefits that no other audio plugin does;
Customisable: 4 different shoe types, 7 surface types, and controls for pace, step firmness, steadiness, etc.
Convenient: Easy to set up, comes with 12 presets to get started in no time.
Versatile: Automatic and Manual modes can be added to any element in a game scene.
Lightweight: Uses very little less disk space; the entire code takes about the same space as one footstep sample.
In a research paper soon to appear at the 152nd Audio Engineering Society Convention, we tried a different approach. We implemented multilayer neural network architectures for footstep synthesis and compared the results with real recordings and various sound synthesis methods, including Nemisindo’s online implementation. The neural approach is not yet applicable to most sound design problems, since it does not offer parametric control. But the listening test was very useful. It showed that Nemisindo’s procedural approach outperformed all other traditional sound synthesis approaches, and gave us insights that led to further improvements.
Here’s a short video introducing the Unity plugin:
And a video introducing it for Unreal
And a nice tutorial video on how to use it in Unreal
So please check it out. Its a big footstep forward in procedural and adaptive sound design (sorry, couldn’t resist the wordplay 😁).
Footstep sounds are one of the most widely used sound effects in film, TV and game sound design. Great footstep sound effects are often needed, from the creeping, ominous footsteps in a horror film to the thud clunk of an armored soldier going into battle in a sci-fi action game.
But its not easy. As Andy Farnell pointed out in Designing Sound (which has a whole chapter on footstep synthesis), there are lots of issues with using recorded footstep samples in games. Some early games would use just one sample, making a character sound like he or she had two left (or two right) feet. To get more realistic variation, you need several different samples for each character, for each foot, for each surface, at different paces. And so one needs to store hundreds of footstep samples. Even then, repetition becomes a problem.
And we have also been looking at a new approach to footstep synthesis, based on multi-layer neural networks.
To investigate this, we have prepared a listening test comparing several different footstep synthesis approaches, as well as real recordings. The study consists of a short multi-stimulus listening test, preceded by a simple questionnaire. It takes place entirely online from your own computer. All that is needed to participate is; • A computer with an internet connection and modern browser • A pair of headphones • No history of hearing loss The duration of the study is roughly 10 minutes. We are very grateful for any responses.The study is accessible here: http://webprojects.eecs.qmul.ac.uk/mc309/FootEval/test.html?url=tests/ape_footsteps.xml
If you have any questions or feedback, please feel free to email Marco Comunità at m.comunita@qmul.ac.uk
Today one of our PhD student researchers, Marco Martinez Ramirez, successfully defended his PhD. The form of these exams, or vivas, varies from country to country, and even institution to institution, which we discussed previously. Here, its pretty gruelling; behind closed doors, with two expert examiners probing every aspect of the PhD. And it was made even more challenging since it was all online due to the virus situation.
Marco’s PhD was on ‘Deep learning for audio effects modeling.’
Audio effects modeling is the process of emulating an audio effect unit and seeks to recreate the sound, behaviour and main perceptual features of an analog reference device. Both digital and analog audio effect units transform characteristics of the sound source. These transformations can be linear or nonlinear, time-invariant or time-varying and with short-term and long-term memory. Most typical audio effect transformations are based on dynamics, such as compression; tone such as distortion; frequency such as equalization; and time such as artificial reverberation or modulation based audio effects.
Simulation of audio processors is normally done by designing mathematical models of these systems. Its very difficult because it seeks to accurately model all components within the effect unit, which usually contains mechanical elements together with nonlinear and time-varying analog electronics. Most audio effects models are either simplified or optimized for a specific circuit or effect and cannot be efficiently translated to other effects.
Marco’s thesis explored deep learning architectures for audio processing in the context of audio effects modelling. He investigated deep neural networks as black-box modelling strategies to solve this task, i.e. by using only input-output measurements. He proposed several different DSP-informed deep learning models to emulate each type of audio effect transformations.
Marco then explored the performance of these models when modeling various analog audio effects, and analyzed how the given tasks are accomplished and what the models are actually learning. He investigated virtual analog models of nonlinear effects, such as a tube preamplifier; nonlinear effects with memory, such as a transistor-based limiter; and electromechanical nonlinear time-varying effects, such as a Leslie speaker cabinet and plate and spring reverberators.
Marco showed that the proposed deep learning architectures represent an improvement of the state-of-the-art in black-box modeling of audio effects and the respective directions of future work are given.
His research also led to a new start-up company, TONZ, which build on his machine learning techniques to provide new audio processing interactions for the next generation of musicians and music makers.
Here’s a list of some of Marco’s papers that relate to his PhD research while a member of the Intelligent Sound Engineering team.
M. A. Martinez Ramirez, E. Benetos, J. D. Reiss, time-varying and nonlinear audio processing using deep neural networks, patent application number PCT/GB2020/051150, 2020
Ryan Stables is an occasional collaborator and all around brilliant person. He started the annual Workshop on Intelligent Music Production (WIMP) in 2015. Its been going strong ever since, with the 5th WIMP co-located with DAFx, this past September. The workshop series focuses on the application of intelligent systems (including expert systems, machine learning, AI) to music recording, mixing, mastering and related aspects of audio production or sound engineering.
Ryan had the idea for a book about the subject, and myself (Josh Reiss) and Brecht De Man (another all around brilliant person) were recruited as co-authors. What resulted was a massive amount of writing, editing, refining, re-editing and so on. We all contributed big chunks of content, but Brecht pulled it all together and turned it into something really high quality giving a comprehensive overview of the field, suitable for a wide range of audiences.
And the book is finally published today, October 31st! Its part of the AES Presents series by Focal Press, a division of Routledge. You can get it from the publisher, from Amazon or any of the other usual places.
And here’s the official blurb
Intelligent Music Production presents the state of the art in approaches, methodologies and systems from the emerging field of automation in music mixing and mastering. This book collects the relevant works in the domain of innovation in music production, and orders them in a way that outlines the way forward: first, covering our knowledge of the music production processes; then by reviewing the methodologies in classification, data collection and perceptual evaluation; and finally by presenting recent advances on introducing intelligence in audio effects, sound engineering processes and music production interfaces.
Intelligent Music Production is a comprehensive guide, providing an introductory read for beginners, as well as a crucial reference point for experienced researchers, producers, engineers and developers.
This afternoon one of our PhD student researchers, Will Wilkinson, successfully defended his PhD. The form of these exams, or vivas, varies from country to country, and even institution to institution, which we discussed previously. Here, its pretty gruelling; behind closed doors, with two expert examiners probing every aspect of the PhD.
Will’s PhD was on ‘Gaussian Process Modelling for Audio Signals.’
Audio signals are characterised and perceived based on how their spectral make-up changes with time. Latent force modelling assumes these characteristics come about as a result of a common input function passing through some input-output process. Uncovering the behaviour of these hidden spectral components is at the heart of many applications involving sound, but is an extremely difficult task given the infinite number of ways any signal can be decomposed.
Will’s thesis studies the application of Gaussian processes to audio, which offer a way to specify probabilities for these functions whilst encoding prior knowledge about sound, the way it behaves, and the way it is perceived. Will advanced the theory considerably, and tested his approach for applications in sound synthesis, denoising and source separation tasks, among others.
W. J. Wilkinson, J. D. Reiss, D. Stowell, ‘A Generative Model for Natural Sounds Based on Latent Force Modelling,’ Arxiv pre-print version. International Conference on Latent Variable Analysis and Signal Separation, Guildford, UK, July 2018.
W. J. Wilkinson, Michael Riis Andersen, Joshua D. Reiss, Dan Stowell, and Arno Solin, “End-to-End Probabilistic Inference for Non-stationary Audio Analysis” Int. Conference on Machine Learning (ICML), 2019
I became a professor last year, which is quite a big deal here. On April 17th, I gave my Inaugural lecture, which is a talk on my subject area to the general public. I tried to make it as interesting as possible, with sound effects, videos, a live experiment and even a bit of physical comedy. Here’s the video, and below I have a (sort of) transcript.
The Start
What did you just hear, what’s the weather like outside? Did that sound like a powerful, wet storm with rain, wind and thunder, or did it sound fake, was something not quite right? All you had was nearly identical, simple signals from each speaker, and you only received two simple, nearly identical signals, one to each ear. Yet somehow you were able to interpret all the rich details, know what it was and assess the quality.
Over the next hour or so, we’ll investigate the research that links deep understanding of sound and sound perception to wonderful new audio technologies. We’ll look at how market needs in the commercial world are addressed by basic scientific advances. We will explore fundamental challenges about how we interact with the auditory world around us, and see how this leads to new creative artworks and disruptive innovations.
Sound effect synthesis
But first, lets get back to the storm sounds you heard. Its an example of a sound effect, like what might be used in a film. Very few of the sounds that you hear in film or TV, and more and more frequently, in music too, are recorded live on set or on stage.
Such sounds are sometimes created by what is known as Foley, named after Jack Foley, a sound designer working in film and radio from the late 1920s all the way to the early 1960s. In its simplest form, Foley is basically banging pots and pans together and sticking a microphone next to it. It also involves building mechanical contraptions to create all sorts of sounds. Foley sound designers are true artists, but its not easy, its expensive and time consuming. And the Foley studio today looks almost exactly the same as it did 60 years ago. The biggest difference is that the photos of the Foley studios are now in colour.
But most sound effects come from sample libraries. These consist of tens or hundreds of thousands of high quality recordings. But they are still someone else’s vision of the sounds you might need. They’re never quite right. So sound designers either ‘make do’ with what’s there, or expend effort trying to shape them towards some desired sound. The designer doesn’t have the opportunity to do creative sound design. Reliance on pre-recorded sounds has dictated the workflow. The industry hasn’t evolved, we’re simply adapting old ways to new problems.
In contrast, digital video effects have reached a stunning level of realism, and they don’t rely on hundreds of thousands of stock photos, like the sound designers do with sample libraries. And animation is frequently created by specifying the scene and action to some rendering engine, without designers having to manipulate every little detail.
There might be opportunities for better and more creative sound design. Instead of a sound effect as a chunk of bits played out in sequence, conceptualise the sound generating mechanism, a procedure or recipe that when implemented, produces the desired sound. One can change the procedure slightly, shaping the sound. This is the idea behind sound synthesis. No samples need be stored. Instead, realistic and desired sounds can be generated from algorithms.
This has a lot of advantages. Synthesis can produce a whole range of sounds, like walking and running at any speed on any surface, whereas a sound effect library has only a finite number of predetermined samples. Synthesized sounds can play for any amount of time, but samples are fixed duration. Synthesis can have intuitive controls, like the enthusiasm of an applauding audience. And synthesis can create unreal or imaginary sounds that never existed in nature, a roaring dragon for instance, or Jedi knights fighting with light sabres..
Give this to sound designers, and they can take control, shape sounds to what they want. Working with samples is like buying microwave meals, cheap and easy, but they taste awful and there’s no satisfaction. Synthesis on the other hand, is like a home-cooked meal, you choose the ingredients and cook it the way you wish. Maybe you aren’t a fine chef, but there’s definitely satisfaction in knowing you made it.
This represents a disruptive innovation, changing the marketplace and changing how we do things. And it matters; not just to professional sound designers, but to amateurs and to the consumers, when they’re watching a film and especially, since we’re talking about sound, when they are listening to music, which we’ll come to later in the talk.
That’s the industry need, but there is some deep research required to address it. How do you synthesise sounds? They’re complex, with lots of nuances that we don’t fully understand. A few are easy, like these-
I just played that last one to get rid of the troublemakers in the audience.
But many of those are artificial or simple mechanical sounds. And the rest?
Almost no research is done in isolation, and there’s a community of researchers devising sound synthesis methods. Many approaches are intended for electronic music, going back to the work of Daphne Oram and Delia Derbyshire at the BBC Radiophonics Workshop, or the French Musique Concrete movement. But they don’t need a high level of realism. Speech synthesis is very advanced, but tailored for speech of course, and doesn’t apply to things like the sound of a slamming door. Other methods concentrate on simulating a particular sound with incredible accuracy. They construct a physical model of the whole system that creates the sound, and the sound is an almost incidental output of simulating the system. But this is very computational and inflexible.
And this is where we are today. The researchers are doing fantastic work on new methods to create sounds, but its not addressing the needs of sound designers.
Well, that’s not entirely true.
The games community has been interested in procedural audio for quite some time. Procedural audio embodies the idea of sound as a procedure, and involves looking at lightweight interactive sound synthesis models for use in a game. Start with some basic ingredients; noise, pulses, simple tones. Stir them together with the right amount of each, bake them with filters that bring out various pitches, add some spice and you start to get something that sounds like wind, or an engine or a hand clap. That’s the procedural audio approach.
A few tools have seen commercial use, but they’re specialised and integration of new technology in a game engine is extremely difficult. Such niche tools will supplement but not replace the sample libraries.
A few years ago, my research team demonstrated a sound synthesis model for engine and motor sounds. We showed that this simple software tool could be used by a sound designer to create a diverse range of sounds, and it could match those in the BBC sound effect library, everything from a handheld electric drill to a large boat motor.
This is the key. Designed right, one synthesis model can create a huge, diverse range of sounds. And this approach can be extended to simulate an entire effects library using only a small number of versatile models.
That’s what you’ve been hearing. Every sound sample you’ve heard in this talk was synthesised. Artificial sounds created and shaped in real-time. And they can be controlled and rendered in the same way that computer animation is performed. Watch this example, where the synthesized propeller sounds are driven by the scene in just the same way as the animation was.
It still needs work of course. You could hear lots of little mistakes, and the models missed details. And what we’ve achieved so far doesn’t scale. We can create hundred of sounds that one might want, but not yet thousands or tens of thousands.
But we know the way forward. We have a precious resource, the sound effect libraries themselves. Vast quantities of high quality recordings, tried and tested over decades. We can feed these into machine learning systems to uncover the features associated with every type of sound effect, and then train our models to find settings that match recorded samples.
We can go further, and use this approach to learn about sound itself. What makes a rain storm sound different from a shower? Is there something in common with all sounds that startle us, or all sounds that calm us? The same approach that hands creativity back to sound designers, resulting in wonderful new sonic experiences, can also tell us so much about sound perception.
Hot versus cold
I pause, say “I’m thirsty”. I have an empty jug and pretend to pour
Pretend to throw it at the audience.
Just kidding. That’s another synthesised sound. It’s a good example of this hidden richness in sounds. You knew it was pouring because the gesture helped, and there is an interesting interplay between our visual and auditory senses. You also heard bubbles, splashes, the ring of the container that its poured into. But do you hear more?
I’m going to run a little experiment. I have two sound samples, hot water being poured and cold water being poured. I want you to guess which is which.
I think its fascinating that we can hear temperature. There must be some physical phenomenon affecting the sound, which we’ve learned to associate with heat. But what’s really interesting is what I found when I looked online. Lots of people have discussed this. One argument goes ‘Cold water is more viscuous or sticky, and so it gives high pitched sticky splashes.’ That makes sense. But another argument states ‘There are more bubbles in a hot liquid, and they produce high frequency sounds.’
Wait, they can’t both be right. So we analysed recordings of hot and cold water being poured, and it turns out they’re both wrong! The same tones are there in both recordings, so essentially the same pitch. But the strengths of the tones are subtly different. Some sonic aspect is always present, but its loudness is a function of temperature. We’re currently doing analysis to find out why.
And no one noticed! In all the discussion, no one bothered to do a little critical analysis or an experiment. It’s an example of a faulty assumption, that because you can come up with a solution that makes sense, it should be the right one. And it demonstrates the scientific method; nothing is known until it is tested and confirmed, repeatedly.
Intelligent Music Production
Its amazing what such subtle changes can do, how they can indicate elements that one never associates with hearing. Audio production thrives on such subtle changes and there is a rich tradition of manipulating them to great effect. Music is created not just by the composer and performers. The sound engineer mixes and edits it towards some artistic vision. But phrasing the work of a mixing engineer as an art form is a double-edged sword, we aren’t doing justice to the technical challenges. The sound engineer is after all, an engineer.
In audio production, whether for broadcast, live sound, games, film or music, one typically has many sources. They each need to be heard simultaneously, but can all be created in different ways, in different environments and with different attributes. Some may mask each other, some may be too loud or too quiet. The final mix should have all sources sound distinct yet contribute to a nice clean blend of the sounds. To achieve this is very labour intensive and requires a professional engineer. Modern audio production systems help, but they’re incredibly complex and all require manual manipulation. As technology has grown, it has become more functional but not simpler for the user.
In contrast, image and video processing has become automated. The modern digital camera comes with a wide range of intelligent features to assist the user; face, scene and motion detection, autofocus and red eye removal. Yet an audio recording or editing device has none of this. It is essentially deaf; it doesn’t listen to the incoming audio and has no knowledge of the sound scene or of its intended use. There is no autofocus for audio!
Instead, the user is forced to accept poor sound quality or do a significant amount of manual editing.
But perhaps intelligent systems could analyse all the incoming signals and determine how they should be modified and combined. This has the potential to revolutionise music production, in effect putting a robot sound engineer inside every recording device, mixing console or audio workstation. Could this be achieved? This question gets to the heart of what is art and what is science, what is the role of the music producer and why we prefer one mix over another.
But unlike replacing sound effect libraries, this is not a big data problem. Ideally, we would get lots of raw recordings and the produced content that results. Then extract features from each track and the final mix in order to establish rules for how audio should be mixed. But we don’t have the data. Its not difficult to access produced content. But the initial multitrack recordings are some of the most highly guarded copyright material. This is the content that recording companies can use over and over, to create remixes and remastered versions. Even if we had the data, we don’t know the features to use and we don’t know how to manipulate those features to create a good mix. And mixing is a skilled craft. Machine learning systems are still flawed if they don’t use expert knowledge.
There’s a myth that as long as we get enough data, we can solve almost any problem. But lots of problems can’t be tackled this way. I thought weather prediction was done by taking all today’s measurements of temperature, humidity, wind speed, pressure… Then tomorrow’s weather could be guessed by seeing what happened the day after there were similar conditions in the past. But a meteorologist told me that’s not how it works. Even with all the data we have, its not enough. So instead we have a weather model, based on how clouds interact, how pressure fronts collide, why hurricanes form, and so on. We’re always running this physical model, and just tweaking parameters and refining the model as new data comes in. This is far more accurate than relying on mining big data.
You might think this would involve traditional signal processing, established techniques to remove noise or interference in recordings. Its true that some of what the sound engineer does is correct artifacts due to issues in the recording process. And there are techniques like echo cancellation, source separation and noise reduction that can address this. But this is only a niche part of what the sound engineer does, and even then the techniques have rarely been optimised for real world applications.
There’s also multichannel signal processing, where one usually attempts to extract information regarding signals that were mixed together, like acquiring a GPS signal buried in noise. But in our case, we’re concerned with how to mix the sources together in the first place. This opens up a new field which involves creating ways to manipulate signals to achieve a desired output. We need to identify multitrack audio features, related to the relationships between musical signals, and develop audio effects where the processing on any sound is dependent on the other sounds in the mix.
And there is little understanding of how we perceive audio mixes. Almost all studies have been restricted to lab conditions; like measuring the perceived level of a tone in the presence of background noise. This tells us very little about real world cases. It doesn’t say how well one can hear lead vocals when there are guitar, bass and drums.
Finally, best practices are not understood. We don’t know what makes a good mix and why one production will sound dull while another makes you laugh and cry, even though both are on the same piece of music, performed by competent sound engineers. So we need to establish what is good production, how to translate it into rules and exploit it within algorithms. We need to step back and explore more fundamental questions, filling gaps in our understanding of production and perception. We don’t know where the rules will be found, so multiple approaches need to be taken.
The first approach is one of the earliest machine learning methods, knowledge engineering. Its so old school that its gone out of fashion. It assumes experts have already figured things out, they are experts after all. So lets look at the sound engineering literature and work with experts to formalise their approach. Capture best practices as a set of rules and processes. But this is no easy task. Most sound engineers don’t know what they did. Ask a famous producer what he or she did on a hit song and you often get an answer like ‘I turned the knob up to 11 to make it sound phat.” How do you turn that into a mathematical equation? Or worse, they say it was magic and can’t be put into words.
To give you an idea, we had a technique to prevent acoustic feedback, that high pitched squeal you sometimes hear when a singer first approaches a microphone. We thought we had captured techniques that sound engineers often use, and turned it into an algorithm. To verify this, I was talking to an experienced live sound engineer and asked when was the last time he had feedback at one of the gigs where he ran the sound. ‘Oh, that never happens for me,’ he said. That seemed strange. I knew it was a common problem. ‘Really, never ever?’ ‘No, I know what I’m doing. It doesn’t happen.’ ‘Not even once?’ ‘Hmm, maybe once but its extremely rare.’ ‘Tell me about it.’ ‘Well, it was at the show I did last night…’! See, it’s a tricky situation. The sound engineer does have invaluable knowledge, but also has to protect their reputation as being one of a select few that know the secrets of the trade.
So we’re working with domain experts, generating hypotheses and formulating theories. We’ve been systematically testing all the assumptions about best practices and supplementing them with lots of listening tests. These studies help us understand how people perceive complex sound mixtures and identify attributes necessary for a good sounding mix. And we know the data will help. So we’re also curating multitrack audio, with detailed information about how it was recorded, often with multiple mixes and evaluations of those mixes.
By combining these approaches, my team have developed intelligent systems that automate much of the audio and music production process. Prototypes analyse all incoming sounds and manipulate them in much the same way a professional operates the controls at a mixing desk.
I didn’t realise at first the importance of this research. But I remember giving a talk once at a convention in a room that had panel windows all around. The academic talks are usually half full. But this time it was packed, and I could see faces outside all pressed up against the windows. They all wanted to find out about this idea of automatic mixing. Its a unique opportunity for academic research to have transformational impact on an entire industry. It addresses the fact that music production technologies are often not fit for purpose. Intelligent mixing systems automate the technical and mundane, allowing sound engineers to work more productively and creatively, opening up new opportunities. Audio quality could be improved, amateur musicians can create high quality mixes of their content, small venues can put on live events without needing a professional engineer, time and preparation for soundchecks could be drastically reduced, and large venues and broadcasters could significantly cut manpower costs.
Its controversial. We once entered an automatic mix in a student recording competition as a sort of Turing Test. Technically, we were cheating, because all the mixes were supposed to be made by students, but in our case it was made by an ‘artificial intelligence’ created by a student. We didn’t win of course, but afterwards I asked the judges what they thought of the mix, and then told them how it was done. The first two were surprised and curious when I told them how it was done. But the third judge offered useful comments when he thought it was a student mix. But when I told him that it was an ‘automatic mix’, he suddenly switched and said it was rubbish and he could tell all along.
Mixing is a creative process where stylistic decisions are made. Is this taking away creativity, is it taking away jobs? Will it result in music sounding more the same? Such questions come up time and time again with new technologies, going back to 19th century protests by the Luddites, textile workers who feared that time spent on their skills and craft would be wasted as machines could replace their role in industry.
These are valid concerns, but its important to see other perspectives. A tremendous amount of audio production work is technical, and audio quality would be improved by addressing these problems. As the graffiti artist Banksy said;
“All artists are willing to suffer for their work. But why are so few prepared to learn to draw?” – BaNKSY
Creativity still requires technical skills. To achieve something wonderful when mixing music, you first have to achieve something pretty good and address issues with masking, microphone placement, level balancing and so on.
The real benefit is not replacing sound engineers. Its dealing with all those situations when a talented engineer is not available; the band practicing in the garage, the small pub or restaurant venue that does not provide any support, or game audio, where dozens of incoming sounds need to be mixed and there is no miniature sound guy living inside the games console.
High resolution audio
The history of audio production is one of continual innovation. New technologies arise to make the work easier, but artists also figure out how to use that technology in new creative ways. And the artistry is not the only element music producers care about. They’re interested, some would say obsessed, with fidelity. They want the music consumed at home to be as close as possible to the experience of hearing it live. But we consume digitial audio. Sound waves are transformed into bits and then transformed back to sound when we listen. We sample sound many times a second and render each sample with so many bits. Luckily, there is a very established theory on how to do the sampling.
We only hear frequencies up to about 20 kHz. That’s a wave which repeats 20,000 times a second. There’s a famous theorem by Claude Shannon and Harry Nyquist which states that you need twice that number of samples a second to fully represent a signal up to 20 kHz, so sample at 40,000 samples a second, or 40 kHz. So the standard music format, 16 bit samples and 44.1 kHz sampling rate, should be good enough.
But most music producers want to work with higher quality formats and audio companies make equipment for recording and playing back audio in these high resolution formats. Some people swear they hear a difference, others say it’s a myth and people are fooling themselves. What’s going on? Is the sampling theorem, which underpins all signal processing, fundamentally wrong? Have we underestimated the ability of our own ears and in which case the whole field of audiology is flawed? Or could it be that the music producers and audiophiles, many of whom are renowned for their knowledge and artistry, are deluded?
Around the time I was wondering about this, I went to a dinner party and was sat across from a PhD student. His PhD was in meta-analysis, and he explained that it was when you gather all the data from previous studies on a question and do formal statistical analysis to come up with more definitive results than the original studies. It’s a major research method in evidence-based medicine, and every few weeks a meta-analysis makes headlines because it shows the effectiveness or lack of effectiveness of treatments.
So I set out to do a meta-analysis. I tried to find every study that ever looked at perception of high resolution audio, and get their data. I scoured every place they could have been published and asked everyone in the field, all around the world. One author literally found his old data tucked away in the back of a filing cabinet. Another couldn’t get permission to provide the raw data, but told me enough about it for me to write a little program that ran through all possible results until it found the details that would reproduce the summary data as well. In the end, I found 18 relevant studies and could get data from all of them except one. That was strange, since it was the most famous study. But the authors had ‘lost’ the data, and got angry with me when I asked them for details about the experiment.
The results of the meta-analysis were fascinating, and not at all what I expected. There were researchers who thought their data had or hadn’t shown an effect, but when you apply formal analysis, it’s the opposite. And a few experiments had major flaws. For instance, in one experiment many of the high resolution recordings were actually standard quality, which means there never was a difference to be perceived. In another, test subjects were given many versions of the same audio, including a direct live feed, and asked which sounds closer to live. People actually ranked the live feed as sounding least close to live, indicating they just didn’t know what to listen for.
As for the one study where the authors lost their data? Well, they had published some of it, but it basically went like this. 55 participants listened to many recordings many times and could not discriminate between high resolution and standard formats. But men discriminated more than women, older far more than younger listeners, audiophiles far more than nonexperts. Yet only 3 people ever guessed right more than 6 times out of 10. The chance of all this happening by luck if there really was no difference is less likely than winning the lottery. Its extremely unlikely even if there was a difference to be heard. Conclusion: they faked their data.
And this was the study which gave the most evidence that people couldn’t hear anything extra in high resolution recordings. In fact the studies with the most flaws were those that didn’t show an effect. Those that found an effect were generally more rigourous and took extra care in their design, set-up and analysis. This was counterintuitive. People are always looking for a new cure or a new effect. But in this case, there was a bias towards not finding a result. It seems researchers wanted to show that the claims of hearing a difference are false.
The biggest factor was training. Studies where subjects, even those experienced working with audio, just came in and were asked to state when two versions of a song were the same, rarely performed better than chance. But if they were told what to listen for, given examples, were told when they got it right or wrong, and then came back and did it under blind controlled conditions, they performed far better. All studies where participants were given training gave higher results than all studies where there was no training. So it seems we can hear a difference between standard and high resolution formats, we just don’t know what to listen for. We listen to music everyday, but we do it passively and rarely focus on recording quality. We don’t sit around listening for subtle differences in formats, but they are there and they can be perceived. To audiophiles, that’s a big deal.
In 2016 I published this meta-analysis in the Journal of the Audio Engineering Society, and it created a big splash. I had a lot of interviews in the press, and it was discussed on social media and internet forums. And that’s when I found out, people on the internet are crazy! I was accused of being a liar, a fraud, paid by the audio industry, writing press releases, working the system and pushing an agenda. These criticisms came from all sides, since differences were found which some didn’t think existed, but they also weren’t as strong as others wanted them to be. I was also accused of cherry-picking the studies, even though one of the goals of the paper was to avoid exactly that, which is why I included every study I could find.
But my favorite comment was when someone called me an ‘intellectually dishonest placebophile apologist’. Whoever wrote that clearly spent time and effort coming up with a convoluted insult.
It wasn’t just people online who were crazy. At an audio engineering society convention, two people were discussing the paper. One was a multi-grammy award winning mixing engineer and inventor, the other had a distinguished career as chief scientist at a major audio company.
What started as discussion escalated to heated argument, then shouting, then pushing and shoving. It was finally broken up when a famous mastering engineer intervened. I guess I should be proud of this.
I learned what most people already know, how very hard it is to change people’s minds once an opinion has been formed. And people rarely look at the source. Instead, they rely on biased opinions discussing that source. But for those interested in the issue whose minds were not already made up, I think the paper was useful.
I’m trying to figure out why we hear this difference. Its not due to problems with the high resolution audio equipment, that was checked in every study that found a difference. There’s no evidence that people have super hearing or that the sampling theorem is violated. But we need to remove all the high frequencies in a signal before we convert it to digital, even if we don’t hear them. That brings up another famous theorem, the uncertainty principle. In quantum mechanics, it tells us that we can’t resolve a particle’s position and momentum at the same time. In signal processing, it tells us that restricting a signal’s frequency content will make us less certain about its temporal aspects. When we remove those inaudible high frequencies, we smear out the signal. It’s a small effect, but this spreading the sound a tiny bit may be audible.
The End
The sounds around us shape our perception of the world. We saw that in films, games, music and virtual reality, we recreate those sounds or create unreal sounds to evoke emotions and capture the imagination. But there is a world of fascinating phenomena related to sound and perception that is not yet understood. Can we create an auditory reality without relying on recorded samples? Could a robot replace the sound engineer, should it? Investigating such questions has led to a deeper understanding of auditory perception, and has the potential to revolutionise sound design and music production.
What are the limits of human hearing? Do we make far greater use of auditory information than simple models can account for? And if so, can we feed this back for better audio production and sound design?
To answer these questions, we need to look at the human auditory system. Sound waves are transferred to the inner ear, which contains one of the most amazing organs in the human body, the cochlea. 3,500 inner hair cells line the cochlea, and resonate in response to frequencies across the audible range. These hair cells connect to a nerve string containing 30,000 neurons which can fire 600 pulses a second. So the brainstem receives up to 18 million pulses per second. Hence the cochlea is a very high resolution frequency analyser with digital outputs. Audio engineers would pay good money for that sort of thing, and we have two of them, free, inside our heads!
The pulses carry frequency and temporal information about sounds. This is sent to the brain’s auditory cortex, where hearing sensations are stored as aural activity images. They’re compared with previous aural activity images, other sensory images and overall context to get an aural scene representing the meaning of hearing sensations. This scene is made available to other processes in the brain, including thought processes such as audio assessment. It’s all part of 100 billion brain cells with 500 trillion connections, a massively powerful machine to manage body functions, memory and thinking.
These connections can be rewired based on experiences and stimuli. We have the power to learn new ways to process sounds. The perception is up to us. Like we saw with hot and cold water sounds, with perception of sound effects and music production, with high resolution audio, we have the power to train ourselves to perceive the subtlest aspects. Nothing is stopping us from shaping and appreciating a better auditory world.
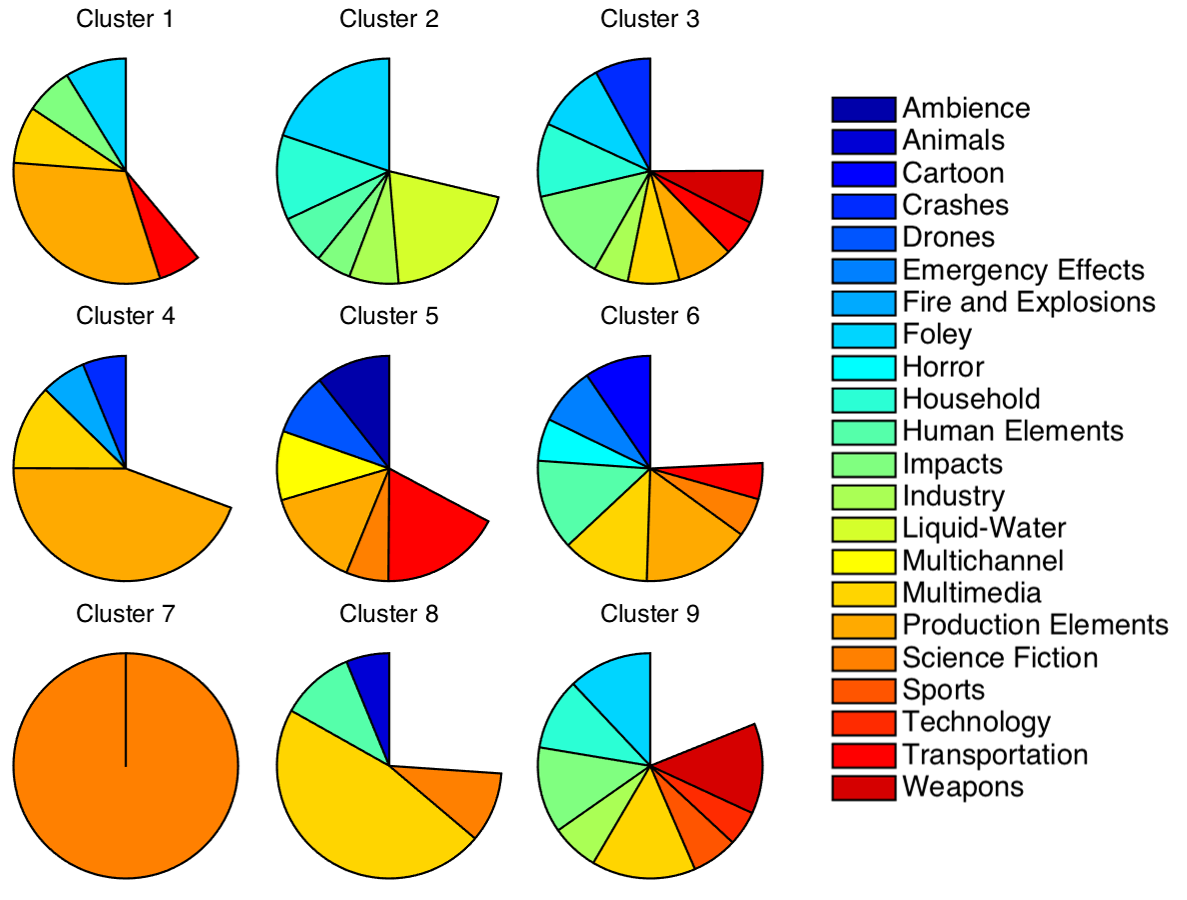
A taxonomy of sound effects is useful for a range of reasons. Sound designers often spend considerable time searching for sound effects. Classically, sound effects are arranged based on some key word tagging, and based on what caused the sound to be created – such as bacon cooking would have the name “BaconCook”, the tags “Bacon Cook, Sizzle, Open Pan, Food” and be placed in the category “cooking”. However, most sound designers know that the sound of frying bacon can sound very similar to the sound of rain (See this TED talk for more info), but rain is in an entirely different folder, in a different section of the SFx Library.
The approach, is to analyse the raw content of the audio files in the sound effects library, and allow a computer to determine which sounds are similar, based on the actual sonic content of the sound sample. As such, the sounds of rain and frying bacon will be placed much closer together, allowing a sound designer to quickly and easily find related sounds that relate to each other.
Here’s a figure from the paper, comparing the generated taxonomy to the original sound effect library classification scheme.