Today one of our PhD student researchers, Angeliki Mourgela, successfully defended her PhD. The form of these exams, or vivas, varies from country to country, and even institution to institution, which we discussed previously. Here, its pretty gruelling; behind closed doors, with two expert examiners probing every aspect of the PhD.
Angeliki’s PhD was on ‘Perceptually Motivated, Intelligent Audio Mixing Approaches for Hearing Loss.’ Aspects of her research have been described in previous blog entries on hearing loss simulation and online listening tests. Angeliki is also a sound engineer and death metal musician.
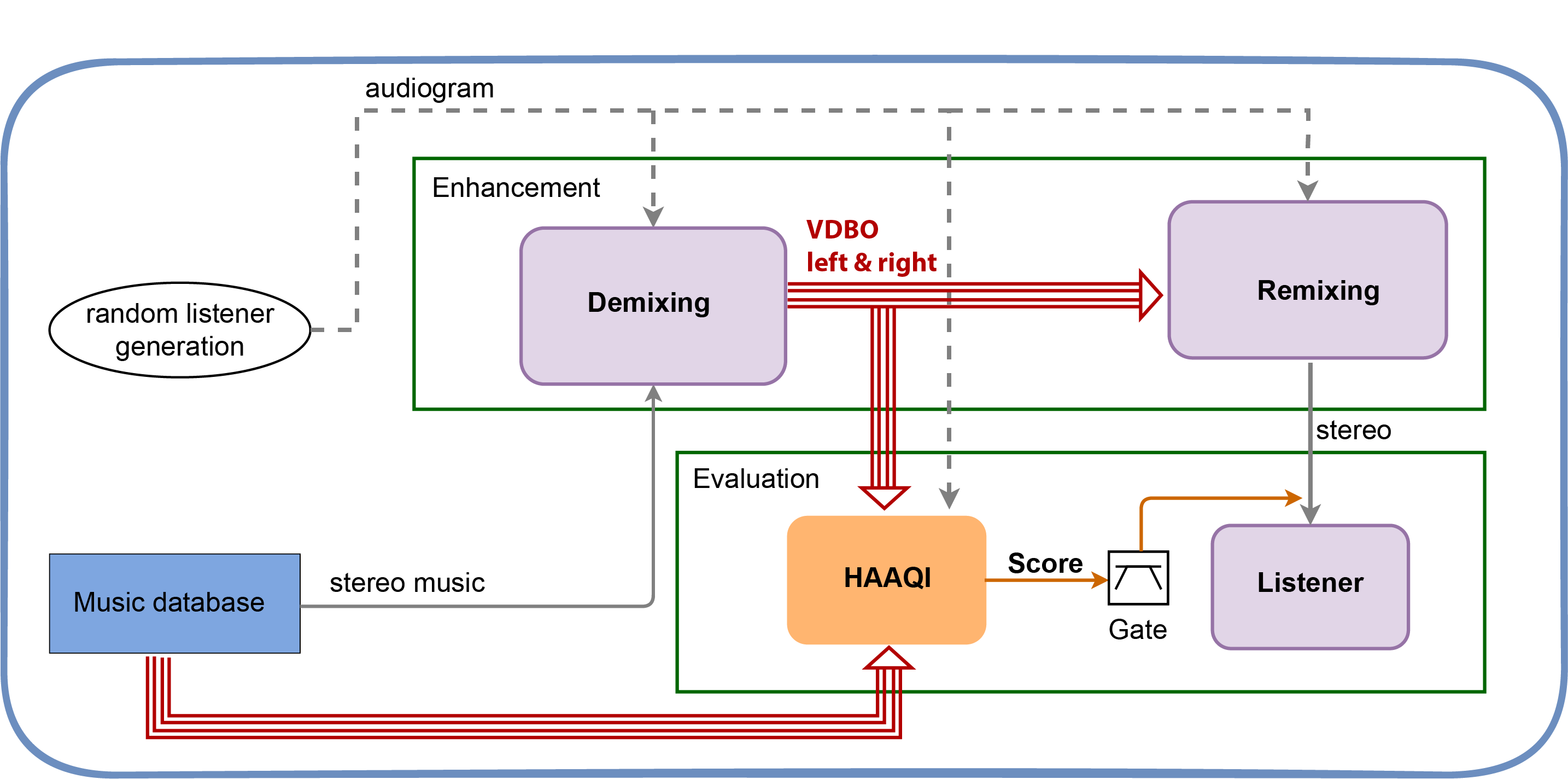
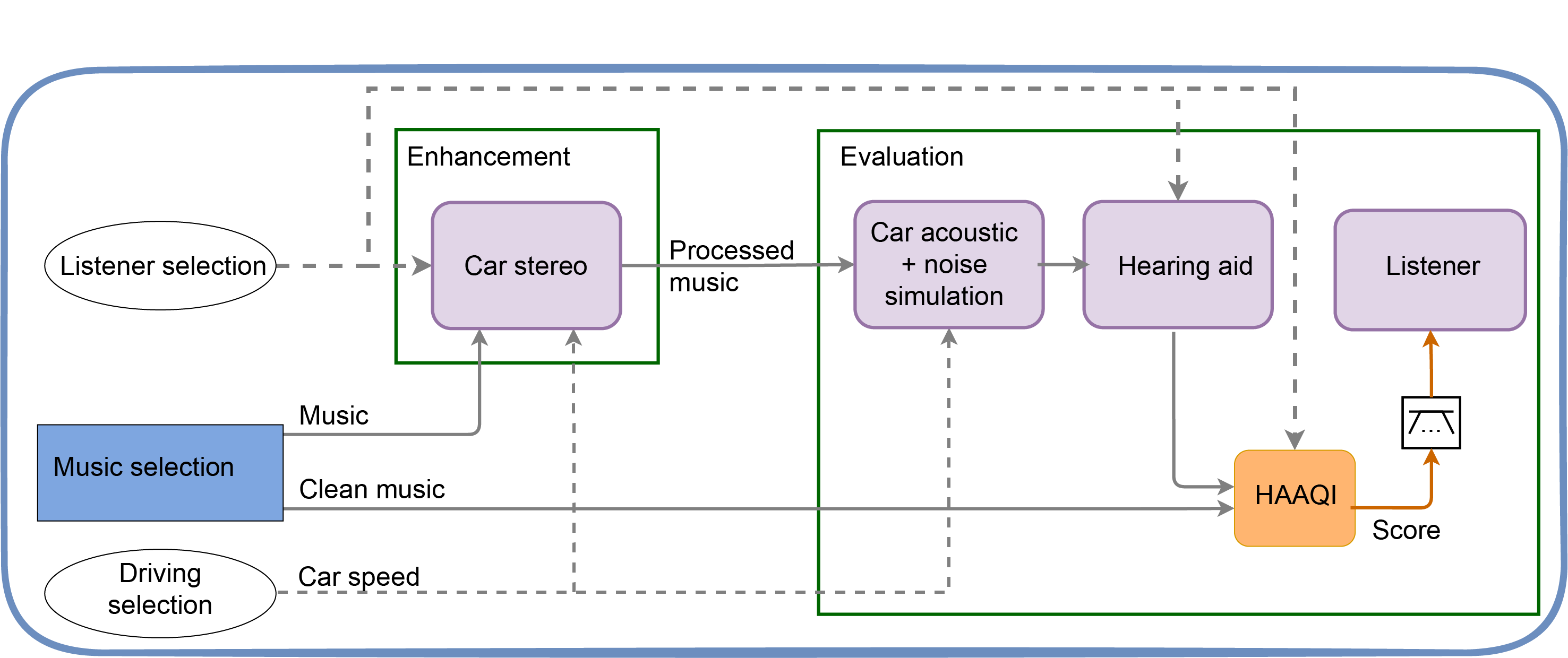
As the population ages, hearing loss is becoming more and more of a concern. Yet mixing engineers, and sound engineers in general, rarely know how the content that they produce would sound to those listeners with hearing loss. Wouldn’t it be great if they could, with the click of a button, hear in real-time how their mix would sound to listeners with different hearing profiles? And could the content be automatically remixed so that the new mix sounds as close as possible for someone with hearing loss as the original mix sounds for someone with normal hearing? That was the motivation for this research.
Angeliki’s thesis explored perceptually motivated intelligent approaches to audio mixing for listeners with hearing loss, through use of a hearing loss simulator as a referencing tool for manual and automatic audio mixing. She designed a real-time hearing loss simulation and tested for its accuracy and effectiveness through the conduction of listening studies with participants with real and simulated hearing loss. The simulation was used by audio engineering students and professionals, in order to see how engineers might combat the effects of hearing loss while mixing content through the simulation.
The extracted practices were then used to inform intelligent audio production approaches for hearing loss.
Angeliki now works for RoEx Audio, a start-up company based partly on research done here. We discussed RoEx in a previous blog entry.
Here’s a video with Angeliki demonstrating an early version of her hearing loss simulator plugin.
The simulator won First Place in the Matlab Student Plugin Competition, at the 149th AES Convention, Oct. 2020. It was also used in an episode of the BBC drama Casualty to let the audience hear the world as heard by a character with severe hearing loss.
And finally, here are a few of her publications
- A. Mourgela, M. Vikelis, and J. D. Reiss, Investigation of Frequency-Specific Loudness Discomfort Levels in Listeners With Migraine: A Case–Control Study. Ear and Hearing (10.1097), February 15, 2023.
- X. Liu, J. D. Reiss, A. Mourgela, “An automatic mixing system for teleconferencing“, 153rd Audio Engineering Society Convention, Oct., 2022.
- A. Mourgela, T. Agus and J. D. Reiss, “Investigation of a real-time hearing loss simulation for use in audio production,” 149th AES Convention, 2020
- A. Mourgela, T. Agus and J. D. Reiss, “Perceptually Motivated Hearing Loss Simulation for Audio Mixing Reference,” 147th AES Convention, 2019
Many thanks also to Angeliki’s collaborators, especially Dr. Trevor Agus, who offered great advice and proposed research directions, Dr. Lorenzo Picinali, who collaborated on some recent evaluation of hearing loss simulators, and Matt Paradis and others from BBC, who supported this work.